-de8bd8f33c3e44a59907dafe1884f228.png)




如果想要在自己的 Linux 系统上面跑网页服务器(WWW server)这项服务,那么我应该要做些什么事呢?当然就需要安装网页服务器的软件呀(如 apache)!如果自己的服务器上面没有这个软件的话,那当然也就无法启用 WWW 的服务了!所以,想要在你的 Linux 上面进行一些有的没的功能,学会如何安装软件是很重要的一个课题!
咦!安装软件有什么难的?在 Windows 系统上面安装软件时,不是只要一直给他按下一步就可以安装妥当了吗?话是这样说没错,不过,也由于如此,所以在 Windows 系统上面的软件都是一模一样的,也就是说,你无法修改该软件的源代码,因此,万一你想要增加或者减少该软件的某些功能时,大概只能求助于当初发行该软件的厂商了!
或许你会说:”唉呦! 我不过是一-般人,不会用到多余的功能,所以不太可能会更动到程序代码的部分吧?“。如果你这么想的话,很抱歉~是有问题的!怎么说呢?像目前网络上面的病毒、黑客软件、臭虫程序等等,都可能对你的主机上面的某些软件造成影响,导致主机的当机或者是其他数据损毁等等的伤害。如果你可以藉由安全信息单位所提供的修订方式进行修改,那么你将可以很快速的自
行修补好该软件的漏洞,而不必一定要等到软件开发商提供修补的程序包呢!要知道,提早填坑是很重要的一件事。
并不是软件开发商故意要搞出一个有问题的软件,而是某些程序代码当初设计时可能没有考虑周全,或者是程序代码与操作系统的权限设定并不相同,所导致的一些漏洞。当然,也有可能是 cracker 透过某些攻击程序测试到程序的不周全所致。无论如何, 只要有网络存在的一天,可以想象的到,程序的漏洞永远补不完!但能补多少就补多少吧!
什么是开放源码、编译程序与可执行文件
在讨论程序代码是什么之前,我们先来谈论一下什么是可执行文件?我们知道,在 Linux 系统上面,一个文件能不能被执行看的是有没有可执行的那个权限(具有x permission),不过,Linux 系统上真
正认识的可执行文件其实是二进制文件( binary program),例如 /usr/bin/passwd, /bin/touch 这些个文
件即为二进制程序代码。
或许你会说 shell scripts 不是也可以执行吗?其实 shell scripts 只是利用 shell (例如 bash) 这支程
序的功能进行解释执行,而最终执行的除了 bash 提供的功能外,仍是呼叫一些已经编译好的二进
制程序来执行的。当然啦, bash 本身也是一支二进制程序啊!那么我怎么知道一个文件是否为
binary 呢?使用 file 命令就可以查看,下面来测试一下。
先以系统的文件测试看看:
[root@localhost ~]# file /bin/bash
/bin/bash: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), dynamically linked (uses shared libs), for GNU/Linux 2.6.32, BuildID[sha1]=9223530b1aa05d3dbea7e72738b28b1e9d82fbad, stripped
如果是系统提供的 /etc/init.d/network 呢?
[root@localhost ~]# file /etc/init.d/network
/etc/init.d/network: Bourne-Again shell script, ASCII text executable
看到了吧!如果是 binary 而且是可以执行的时候,他就会显示执行文件类别 ELF 64-bit LSB executable,同时会说明是否使用动态函式库(sharedlibs),而如果是一般的 script,那他就会显示出 text executable 之类的字样!
事实上,
network的数据显示出Bourne. Again ...那一行,是因为你的 script 上面第一行有标注#!/bin/bash的缘故,如果你将 script 的第一行拿掉,那么不管/etc/init.d/network的权限为何,他其实
显示的是 ASCI 文本文件的信息。
既然 Linux 操作系统真正认识的其实是 binary program,那么我们是如何做出这样的一支 binary 的程序呢?
首先,我们必须要写程序,用什么东西写程序?就是一般的文本编辑器,如 VIM、Nano。写完的程序就是所谓的源代码,这个程序代码文件其实就是一般的纯文本文件。在完成这个原代码文件的编写之后,接下来就是要将这个文件编译成为操作系统看的懂
的 binary program 了!而要编译自然就需要编译程序来支持,经过编译程序的编译与连结之后,就会产生一个可以执行的 binary program。
举个例子来说,在 Linux 上面最标准的程序语言为 C,所以我使用 C 的语法进行源代码的书写,写完之后,以 Linux 上标准的 C 语言编译程序 gcc 这个程序来编译,就可以制作一个可以执行的 binary program 了。整个的流程有点像这样:
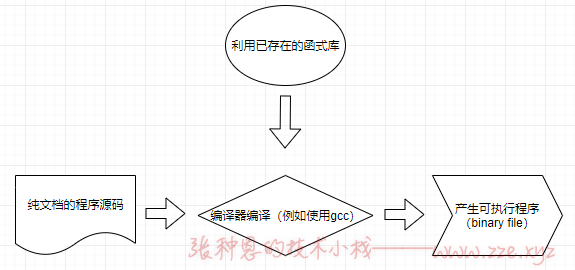
事实上,在编译的过程当中还会产生所谓的目标文件(Object file),这些文件是以 *.o 的扩展名样式
存在的。至于 C 语言的源码文件通常以 *.c 作为扩展名。此外,有的时候,我们会在程序当中引用、呼叫其他的外部子程序,或者是利用其他软件提供的函数功能,这个时候,我们就必须要在编译的过程当中,将该函式库给它加进去,如此一来,编译程序就可以将所有的程序代码与函式库作一个连结(Link)以产生正确的可执行文件。
总之,我们可以这么说:
- 开放源码:就是程序代码,写给人类看的程序语言,但机器并不认识,所以无法执行;
- 编译程序:将程序代码转译成为机器看的懂得语言,就类似翻译者的角色;
- 可执行文件:经过编译程序变成二进制程序后,机器看的懂所以可以执行的文件。
什么是函式库
在前一小节的示意图中,在编译的过程里面有提到函式库这东西。什么是函式库呢?
Linux 核心提供了相当多的函式库来给硬件开发者利用,函式库又分为动态与静态函式库,这里我们以一个简单的流程图,来示意一个有呼叫外部函式库的程序的执行情况。
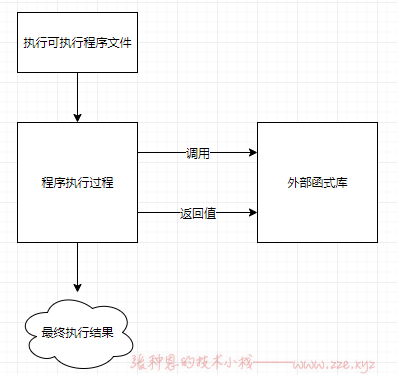
很简单的示意图,如果要在程序里面加入引用的函式库,就需要如图所示,即在编译的过程当中,就需要加入函式库的相关设定。事实上,Linux 的核心提供了很多的核心相关函式库,这些核心功能在设计硬件的驱动程序时是相当有用的信息,这些核心相关信息大多放置在 /usr/include,/usr/lib,/usr/lib64 里面。反正我们可以简单的这么想:
- 函式库:就类似子程序的角色,可以被调用来执行的一段功能函数。
什么是make与configure
事实上,使用类似 gcc 的编译程序来进行编译的过程并不简单,因为一套软件并不会仅有一个程序源代码文件,而是有一堆程序代码文件。所以除了每个主程序与子程序均需要写上一笔编译过程的指令外,还需要写上最终的链接程序。程序代码精简的时候还好,如果是类似 www 服务器软件(如 Apache),或者是类似内核的源代码,动则数百 MBytes 的数据量,编译指令会写到疯掉~这个时候,我们就可以使用 make 这个指令的相关功能来进行编译过程的指令简化了!
当执行 make 时,make 会在当时的目录下搜寻 Makefile (or makefile)这个文本文件,而 Makefile 里
面则记录了源码如何编译的详细信息!make 会自动地判别源码是否经过变动了,而自动更新执行档,是软件工程师相当好用的一个辅助工具!
咦! make 是一个程序,会去找 Makefile ,那 Makefile 怎么写?通常软件开发商都会写一支侦测程序来侦测用户的作业环境,以及该作业环境是否有软件开发商所需要的其他功能,该侦测程序侦测完毕后,就会主动的建立这个 Makefile 的规则文件。通常这支侦测程序的文件名为 configure 或者是 config。
咦!那为什么要侦测作业环境呢?不是每个 Linux distribution 都使用同样的核心吗?
但你得要注意,不同版本的核心所使用的系统调用可能不相同,而且每个软件所依赖的函式库也不相同,同时,软件开发商不会仅针对 Linux 开发,而是会针对整个 Unix-Like 做开发。所以它也必须要侦测该操作系统平台有没有提供合适的编译程序才行!所以当然要侦测环境啊。一般来说, 侦测程序会侦测的数据大约有底下这些:
- 是否有适合的编译程序可以编译本软件的程序代码;
- 是否已经存在本软件所需要的函式库,或其他需要的依赖软件;
- 操作系统平台是否适合本软件,包括 Linux 的核心版本;
- 核心的表头定义(header include)是否存在(驱动程序必须要的侦测)。
至于 make 与 configure 运作流程的相关性,我们可以使用底下的图示来示意。下图中,你要进行的任务其实只有两个,一个是执行 configure 来建立 Makefile ,这个步骤一定要成功!成功之后再以 make 来调用所需要的数据来编译即可,非常简单!

由于不同的 Linux distribution 的函式库文件所放置的路径,或者是函式库的文件名,或者是预设安装的编译程序,以及核心的版本都不相同,因此理论上,你无法在 CentOS 7.x 上面编译出 binary program 后,还将他拿到 SuSE. 上面执行,这个动作通常是不可能成功的!因为呼叫的目标函式库位置可能不同 ,核心版本更不可能相同!所以能够执行的情况是微乎其微!所以同一套软件要在不同的平台上面执行时,必须要重复编译!所以才需要源码文件嘛~
什么是 Tarball 的软件
从前面几个小节的说明来看,我们知道所谓的源代码,其实就是一些写满了程序代码的纯文本文件。而纯文本文件在网络上其实是很浪费带宽的一种文件格式。所以如果能够将这些源码文件通过文件的打包与压缩技术来将文件的数量与容量减小,不
但让用户容易下载,软件开发商的网站带宽也能够节省很多很多啊!这就是 Tarball 文件的由来。
想一想,一个内核的源代码文件大约要 300 - 500MB 以上,如果每个人都去下载这样的一个核心文件,呵呵~那么网络带宽不被吃的死翘翘才怪。
所谓的 Tarball 文件,其实就是将软件的所有原始码文件先以 tar 打包,然后再以压缩技术来压缩,通常最常见的就是以 gzip 来压缩了。因为利用了 tar 与 gzip 的功能,所以 tarball 文件一般的扩展名就会写成 *.tar.gz 或者是简写为 *.tgz 。不过,近来由于bzip2 与 xz 的压缩率较佳,所以 Tarball 渐渐的以 bzip2 及 xz 的压缩技术来取代 gzip,因此文件名也会变成 *.tar.bz2、*.tar.xz 之类的。
所以说,Tarball 是一个软件包,你将他解压缩之后,里面的文件通常就会有:
- 源代码文件;
- 侦测程序文件(可能是
configure或config等文件名); - 本软件的简易说明与安装说明(
INSTALL或README);
其中最重要的是那个 INSTALL 或者是 README 这两个文件,通常你只要能够参考这两个文件,Tarball 软件的安装是很简单的啦!
如何安装与升级软件
将原始码作了一个简单的介绍,也知道了系统其实认识的可执行文件是 binary program 之后,好了,得要聊一聊,怎么安装与升级一个 Tarball 的软件?为什么要安装一个新的软件呢?当然是因为我们的主机上面没有该软件。那么,为何要升级呢?原因可能有底下这些:
- 需要新的功能,但旧有主机的旧版软件并没有,所以需要升级到新版的软件;
- 旧版本的软件上面可能有安全上的顾虑,所以需要更新到新版的软件;
- 旧版的软件执行效能不彰,或者执行的能力不能让管理者满足。
在上面的需求当中,尤其需要注意的是第二点,当一个软件有安全上的顾虑时,千万不要怀疑,赶紧更新软件吧!否则造成网络危机,那可不是闹着玩的!那么更新的方法有哪些呢?基本上更新的方法可以分为两大类,分别是:
- 直接以源码文件通过编译来安装与升级;
- 直接以编译好的 binary program 来安装与升级;
上面第一点很简单,就是直接以 Tarball 在自己的机器上面进行侦测、编译、 安装与设定等等动作来升级就是了。不过,这样的动作虽然让使用者在安装过程当中具有很高的弹性,但毕竟是比较麻烦一点,如果 Linux distribution 厂商能够针对自己的作业平台先进行编译等过程,再将编译好的 binary program 释出的话,那由于自己的系统与该 Linux distribution 的环境是相同的,所以他所释出的 binary program 就可以在我的机器上面直接安装啦!省略了侦测与编译等等繁杂的过程~
这个预先编译好程序的机制区分于很多 distribution,包括有 RedHat 系统(含 Fedora/CentOS 系列)发展的 RPM 软件管理机制与 yum 在线更新模式;;Debian 使用的 dpkg 软件管理机制与 APT 在线更新模式等等。
由于 CentOS 系统是依循标准的 Linux distribution,所以可以使用 Tarball 直接进行编译的安装与升级,当然也可以使用RPM相关的机制来进行安装与升级。
好了,那么一个软件的 Tarball 是如何安装的呢?基本流程是这样的:
- 将 Tarball 从厂商的官网下载下来;
- 将 Tarball 解开,产生很多的源代码文件;
- 开始以 gcc 进行源代码的编译(会产生目标文件 object files);
- 然后以 gcc 进行函式库、主、子程序的链接,以形成主要的 binary file;
- 将上述的 binary file 以及相关的配置文件安装至自己的主机上面;
上面第 3、4 步骤当中,我们可以透过 make 这个指令的功能来简化他, 所以整个步骤其实是很简单的!只不过你就得需要至少有 gcc 以及 make 这两个软件在你的 Linux 系统里面才行。
评论区