-de8bd8f33c3e44a59907dafe1884f228.png)




keepalived 介绍
keepalived 是什么
keepalived是集群管理中保证集群高可用的一个服务软件,其功能类似于heartbeat,用来防止单点故障。
keepalived 工作原理
keepalived 是以 VRRP 协议为实现基础的,VRRP 全称 Virtual Router Redundancy Protocol,即虚拟路由冗余协议。
虚拟路由冗余协议,可以认为是实现路由器高可用的协议,即将 N 台提供相同功能的路由器组成一个路由器组,这个组里面有一个 master 和多个 backup,master 上面有一个对外提供服务的 vip(该路由器所在局域网内其他机器的默认路由为该 vip),master 会发组播,当 backup 收不到 vrrp 包时就认为 master 宕掉了,这时就需要根据 VRRP 的优先级来选举一个 backup 当 master。这样的话就可以保证路由器的高可用了。
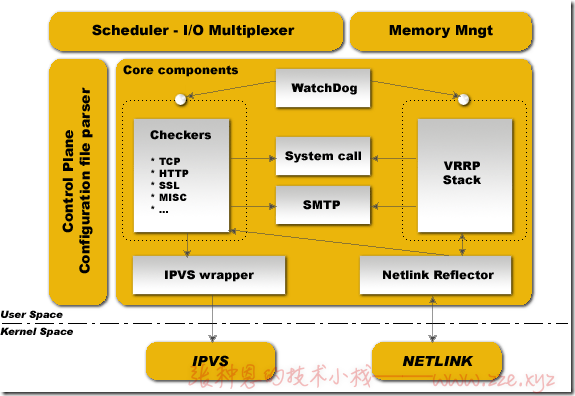
keepalived 主要有三个模块,分别是 core、check 和 vrrp。
- core 模块为 keepalived 的核心,负责主进程的启动、维护以及全局配置文件的加载和解析;
- check 负责健康检查,包括常见的各种检查方式;
- vrrp 模块是来实现 VRRP 协议的;
VRRP 详细可参考『VRRP 技术白皮书』。
keepalived 的配置文件
keepalived 只有一个配置文件 keepalived.conf,里面主要包括以下几个配置区域,分别是 global_defs、static_ipaddress、static_routes、vrrp_script、vrrp_instance 和 virtual_server。
下面为示例配置文件,各配置段及指令的功用以注释的方式描述。
# 全局配置块
global_defs {
# 故障发生时给谁发邮件通知,目标邮件地址可有多个。
notification_email {
acassen@firewall.loc
failover@firewall.loc
sysadmin@firewall.loc
}
# 通知邮件从哪个地址发出。
notification_email_from Alexandre.Cassen@firewall.loc
# 通知邮件的 smtp 地址。
smtp_server 192.168.200.1
# 连接 smtp 服务器的超时时间。
smtp_connect_timeout 30
# 标识本节点的字条串,通常为 hostname,但不一定非得是 hostname,故障发生时,邮件通知会用到。
router_id LVS_DEVEL
}
# 静态地址配置块
static_ipaddress {
# 启动 keepalived 时在本机执行如下命令:
# /sbin/ip addr add 10.210.214.163/24 brd 10.210.214.255 dev eth0
# 关闭 keepalived 时在本机执行如下命令:
# /sbin/ip addr del 10.210.214.163/24 brd 10.210.214.255 dev eth0
10.210.214.163/24 brd 10.210.214.255 dev eth0
}
# 静态路由配置块
static_routes {
# 启动 keepalived 时在本机执行如下命令
# /sbin/ip route add 10.0.0.0/8 via 10.210.214.1 dev eth0
# 关闭 keepalived 时在本机执行如下命令
# /sbin/ip route del 10.0.0.0/8 via 10.210.214.1 dev eth0
10.0.0.0/8 via 10.210.214.1 dev eth0
}
# static_ipaddress、static_routes 这两个块不常用,也没必要使用这俩东东来配置路由和地址吧~~~
# 用来做健康检查的,当时检查失败时会将 vrrp_instance 的 priority 减少相应的值。
vrrp_script chk_down {
script "[[ -f /etc/keepalived/down ]] && exit 1 || exit 0"
interval 1
weight -10
}
# 以上意思是如果 script 中的指令执行失败(退出状态码不为 0),那么相应的 vrrp_instance 的优先级会减少 10 个点。
# vrrp 实例组配置块
vrrp_sync_group VG_1 {
# 下面 group 块将 VI_1 实例和 VI_2 实例配置在同一个组。
# 说一个使用场景,比如要给多台使用 lvs-nat 模型的 director 添加 VIP,此时内网主机的网关就需要同步指向 VIP 所在的 director 的内网地址,
# 即 director 的 VIP 和 DIP 需要同步流动,所以需要将它们定义在一个组中。
group {
VI_1
VI_2
}
# 下面几项的功能和 vrrp_instance 块中的功能相同,只不过在这里它们是针对上述组中定义的所有实例同时生效的。
notify_master /path/to_master.sh
notify_backup /path/to_backup.sh
notify_fault "/path/fault.sh VG_1"
notify /path/notify.sh
smtp_alert
}
# vrrp 实例配置块
vrrp_instance VI_1 {
# 可以是 MASTER 或 BACKUP,不过当其他节点的 keepalived 启动时会将 priority 比较大的节点选举为 MASTER,所以此项其实没有实质用途。
state MASTER
# 设定用来发 VRRP 包的网卡。
interface eth0
# 取值在 0-255 之间,用来区分多个 instance 的 VRRP 组播。
# 注意:不同虚拟路由器中 virtual_router_id 的值不能重复,否则会出错。
# 原因是虚拟 MAC 地址的格式为 00-00-5E-00-01-{VRID},相同即虚拟 MAC 重复了。
virtual_router_id 51
# 配置权重用来选举 master,要成为 master,那么这个选项的值最好高于其他机器 50 个点,该项取值范围是 1-255(在此范围之外会被识别成默认值 100)。
priority 100
# 是否使用 VRRP 的虚拟 MAC 地址。
use_vmac
# 发 VRRP 包的时间间隔,即多久进行一次 master 选举(可以认为是健康查检时间间隔)。
advert_int 1
# authentication 认证区域,认证类型有 PASS 和 HA(IPSEC),推荐使用 PASS(密码只识别前 8 位)。
authentication {
auth_type PASS
auth_pass 1111
}
# 虚拟 IP 地址
virtual_ipaddress {
192.168.200.16
192.168.200.17
192.168.200.18
}
# 虚拟路由,当 IP 漂过来之后需要添加的路由信息。
virtual_routes {
172.16.0.0/12 via 10.210.214.1
192.168.1.0/24 via 192.168.1.1 dev eth1
default via 202.102.152.1
}
# virtual_ipaddress_excluded 发送的 VRRP 包里不包含的 IP 地址,为减少回应 VRRP 包的个数。在网卡上绑定的 IP 地址比较多的时候用。
virtual_ipaddress_excluded {
172.16.1.202
}
# 启用非抢占模式,即允许一个 priority 比较低的节点作为 master,即使有 priority 更高的节点启动。
# 当使用 track_script 时可以不用加 nopreempt,只需要加上 preempt_delay 5,这里的间隔时间要大于 vrrp_script 中定义的时长。
# 首先 nopreempt 必须在 state 为 BACKUP 的节点上才生效,需要将所有节点的 state 都设置为 BACKUP,或者将 master 节点的 priority 设置的比 BACKUP 低。我个人推荐使用将所有节点的 state 都设置成 BACKUP 并且都加上 nopreempt 选项,当想手动将某节点切换为 MASTER 时只需去掉该节点的 nopreempt 选项并且将 priority 改的比其他节点大,然后重新加载配置文件即可。
nopreempt
# master 启动多久之后进行接管资源(VIP/Route 信息等),前提是没有 nopreempt 选项。
preempt_delay 300
# 切换为主节点时所执行的脚本。
notify_master <STRING>|<QUOTED-STRING>
# 切换为备节点时所执行的脚本。
notify_backup <STRING>|<QUOTED-STRING>
# 切换出错时所执行的脚本。
notify_fault <STRING>|<QUOTED-STRING>
# 表示任何一状态切换时都会调用该脚本,并且该脚本在以上三个脚本执行完成之后进行调用,keepalived 会自动传递三个参数($1 = "GROUP"|"INSTANCE",$2 = name of group or instance,$3 = target state of transition(MASTER/BACKUP/FAULT))。
notify <STRING>|<QUOTED-STRING>
# 表示是否开启邮件通知(用全局区域的邮件设置来发通知)。
smtp_alert
# 忽略 VRRP 网卡错误。
dont_track_primary
# 修改 vrrp 组播包的源地址,默认源地址为 master 的 IP(由于是组播,因此即使修改了源地址,该 master 还是能收到回应的)。
mcast_src_ip <IPADDR>
# 绑定 lvs syncd 的网卡。
lvs_sync_daemon_interface eth1
# 调用 vrrp_script 检查脚本块
track_script {
chk_down
}
# 监控以下网卡,如果任何一个不通就会切换到 FAIL 状态。
track_interface {
eth0
eth1
}
# 当切为主状态后多久更新 ARP 缓存,默认 5 秒。
garp_master_delay 10
}
# LVS ipvs 配置
virtual_server 192.168.200.100 443 {
# 延迟轮询时间(单位秒)。
delay_loop 6
# 后端调试算法(load balancing algorithm)。
lb_algo rr
# LVS 调度类型 NAT/DR/TUN。
lb_kind NAT
# 用来给 HTTP_GET 和 SSL_GET 配置请求 header 的。
virtualhost <STRING>
# 当所有 real server 宕掉时,sorry server 顶替。
sorry_server <IPADDR><PORT>
# 掩码
nat_mask 255.255.255.0
persistence_timeout 50
# 使用的协议
protocol TCP
# 真正提供服务的服务器。
real_server 192.168.201.100 443 {
# 权重
weight 1
# 当 real server 启动时执行的脚本。
notify_up <STRING>|<QUOTED-STRING>
# 当 real server 宕掉时执行的脚本。
notify_down <STRING>|<QUOTED-STRING>
# HTTPS 监控检测,除此之外常用的还有 HTTP_GET、TCP_CHECK
SSL_GET {
url {
# 请求 real serserver 上的路径。
path /
# 用 genhash 算出的结果。
digest ff20ad2481f97b1754ef3e12ecd3a9cc
# http 状态码。
status_code <INT>
}
# 健康检查,如果端口通则认为服务器正常。
connect_port <PORT>
# 超时时长。
connect_timeout 3
# 重试次数。
nb_get_retry 3
# 下次重试的时间延迟。
delay_before_retry 3
}
}
}
启用日志记录
keepalived 默认是没启用日志记录的,如果要启用,则需要手动指定记录日志的设施,以将日志记录到自定的 local3 设施为例。
1、修改 /etc/sysconfig/keepalived 配置如下:
KEEPALIVED_OPTIONS="-D -S 3"
这个配置的选项之所以能生效,是因为 keepalived 的 unit 启动文件中有加载
KEEPALIVED_OPTIONS这个变量,对应的 unit 文件为/usr/lib/systemd/system/keepalived.service。
2、然后需要在 rsyslog 配置中添加 local3 设施:
$ vim /etc/rsyslog.conf
local3.* /var/log/keepalived.log
3、重启 rsyslog 服务并启动 keepalived:
$ systemctl restart rsyslog
$ systemctl restart keepalived
当然,如果多台主机都要开启 keepalived 日志,那么每台主机都要做如上修改。
实例
我这里先准备如下 IP 地址的两台主机:
| 主机名 | IP |
|---|---|
| test210 | 10.0.1.210 |
| test205 | 10.0.1.205 |
在两台主机上都启用 keepalived(当然这两台主机上的 keepalived 属于同一组),配置这组 keepalived 的 VIP 为 10.0.1.220,并设置 A 主机的优先级高于 B 主机。
实例一:抢占模式
抢占模式的效果是,当 A 主机宕机时,VIP 将会自动飘到 B 主机,然后当 A 主机启用后,VIP 又会被 A 主机抢占回来,因为 A 主机的优先级更高。
A 主机配置:
global_defs {
router_id test210
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
10.0.1.220
}
}
B 主机配置:
global_defs {
router_id test205
}
vrrp_instance VI_1 {
state BACKUP
interface eth0
virtual_router_id 51
priority 99
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
10.0.1.220
}
}
上面其实有说过当其他节点的 keepalived 启动时会将 priority 比较大的节点选举为 MASTER,此项其实没有实质用途。但是在抢占模式下还是推荐将高优先级的主节点的 state 需指定为 MASTER,备节点的 state 需指定为 BACKUP,这样配置会更加清晰~~~
除了上述的抢占模式还可配置非抢占模式,在非抢占模式下,当 VIP 确定在绑定 A 主机上后,即便有 B 主机上 keepalvied 配置的优先级比 A 主机配置的优先级高,VIP 依旧会绑定在当前 A 主机上,除非 A 主机的 keepalived 服务不可用了,VIP 才会流动到 B 主机。
非抢占模式的配置非常简单,只需要将上述两个主机的配置中的state都设为BACKUP,并在vrrp_instance块中添加nopreempt指令即可,我这里就不再演示啦~~~。
实例二:执行检查脚本
在上面的配置说明中已经有讲到,我们可以通过 vrrp_script 块来指定要执行的脚本或命令,然后通过在 vrrp_instance 块中定义 track_script 块来调用 vrrp_script 块定义的脚本,并且可以定义这个脚本的执行间隔时间,还可以定义当脚本执行失败时对当前的 vrrp_instance 权重(priority)的增降。
直接看实例吧~下面基于「实例一:抢占模式」进行修改,仅修改 A 主机配置,B 主机配置不变。
在 A 主机配置中添加如下 vrrp_script 块,并在 vrrp_instance 中通过 track_script 调用它:
global_defs {
...
}
vrrp_script check_down {
script "[[ -f /etc/keepalived/down ]] && exit 1 || exit 0"
interval 1
weight -3
}
vrrp_instance VI_1 {
...
track_script {
check_down
}
}
下面对如上配置做下解释,首先,在实例一中 A 主机为主节点且它的权重值为 100,B 主机为备节点且它的权重值为 99,我们来通过 check_down 脚本块每秒钟执行一次 [[ -f /etc/keepalived/down ]] && exit 1 || exit 0,即当存在指定文件时,就把命令执行退出码设为非 0,此时对应调用此 vrrp_script 的 vrrp_instance 的权重值就会对应的减 3,在这里也就是 A 主机的权重值 100-3,此时 A 主机的权重值就低于 B 主机的 99,由于此时是抢占模式,VIP 会被 B 主机所抢占。当我们删除 A 主机上的指定文件时,此时脚本的退出执行状态码为 0,则恢复正常的权重值 100,比 B 主机的权重值高,所以此时 B 主机的 VIP 又会被 A 主机抢占回来。
实例三:高可用 LVS
这里我们就基于「lvs-dr」实例来进行修改。
这里主要的几个修改点如下:
- 由于这里我们要给 Director 做高可用,所以我们要在该实例的基础上再添加一个 Director 主机;
- 原来 Director 的 VIP 是我们通过命令手动添加的,而现在我们需要将 VIP 交给 keepalived 管理;
我这里的修改后的主机规划如下:
| IP | 描述 |
|---|---|
| 10.0.1.200 | Director1 |
| 10.0.1.204 | Director2 |
| 10.0.1.201 | Real Server1 |
| 10.0.1.202 | Real Server2 |
这四台主机使用同一个 VIP,并且 RIP、VIP、DIR 在同一网段,这里我们依旧使用之前的 10.0.1.199 作为 VIP。
这里 Real Server 就不用修改了,我们仅需要把原来的 Director 上的 ipvs 规则清空,然后配置一下 keepalived 即可,下面就开始吧~~
下面的操作是在 Director 已经清空 ipvs 规则并且安装好 keepalived 之后进行的。
1、修改 Director1 的 keepalived 配置如下:
global_defs {
router_id director1
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
10.0.1.199/32
}
}
# 配置一个集群服务
virtual_server 10.0.1.199 80 {
# 轮询延迟时间为 6 秒
delay_loop 6
# 调度算法
lb_algo wrr
# lvs 模式/类型
lb_kind DR
# 掩码
netmask 255.255.255.255
# 协议
protocol TCP
# 当 Real Server 都不能正常访问时,返回 sorry_server 指定的内容,前提是指定的 sorry_server 开启了 web 服务
sorry_server 127.0.0.1 80
# 配置第一个 Real Server
real_server 10.0.1.201 80 {
# 权重
weight 1
# 监控检查方式,这里也可以使用 TCP_CHECK,内部只指定超时时间即可
HTTP_GET {
# 配置健康检查的 URL
url {
# 指定 URL
path /
# 当响应状态码为 200 时才视为服务正常
status_code 200
}
# 连接超时时间
connect_timeout 3
# 失败重试次数
nb_get_retry 3
# 重试延迟时间
delay_before_retry 3
}
}
# 配置第二个 Real Server
real_server 10.0.1.202 80 {
weight 2
HTTP_GET {
url {
path /
status_code 200
}
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
}
}
2、修改 Director2 的 keepalived 配置如下:
global_defs {
router_id director2
}
vrrp_instance VI_1 {
state BACKUP
interface eth0
virtual_router_id 51
priority 99
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
10.0.1.199/32
}
}
virtual_server 10.0.1.199 80 {
delay_loop 6
lb_algo wrr
lb_kind DR
netmask 255.255.255.255
protocol TCP
sorry_server 127.0.0.1 80
real_server 10.0.1.201 80 {
weight 1
HTTP_GET {
url {
path /
status_code 200
}
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
}
real_server 10.0.1.202 80 {
weight 2
HTTP_GET {
url {
path /
status_code 200
}
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
}
}
完成上述配置后,启动两个 Director 上的 keepalived 服务,此时两个 Director 上会自动配置上如下 ipvs 规则:
$ ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 10.0.1.199:80 wrr
-> 10.0.1.201:80 Route 1 0 0
-> 10.0.1.202:80 Route 2 0 0
是不是和我们手动通过 ipvsadm 命令添加的规则一模一样~只是这里 Director 的 VIP 是由 keepalived 服务控制流动的,当一个 Director 宕机时,VIP 就会流动到另一个 Director 上,由另一个 Director 正常提供服务,从而完成了 LVS 高可用架构的构建~~~
实例四:高可用 Nginx
对于 Nginx 的高可用其实仅需要在实例一的基础上进行修改,只需要保证 VIP 所在主机上的 Nginx 可用即可。那 keepalived 如何能获知 Nginx 是否可用呢?
我们可以编写一个 shell 脚本,该脚本的功用为判断 Nginx 的状态,当检测到 Nginx 进程不存在或不正常时,就重启 Nginx,如果重启失败,则停止当前主机的 keepalived 服务,如果当前主机的 keepalived 服务不可用了,那么 VIP 将会流动到其它可用的主机上,从而实现 Nginx 的高可用。
实现步骤如下:
1、编写检测 Nginx 健康状态的脚本:
$ cat /scripts/check_nginx.sh
killall -0 nginx
if [ $? -ne 0 ];then
systemctl start nginx
sleep 5
killall -0 nginx
if [ $? -ne 0 ];then
systemctl stop keepalived
fi
fi
killall的0信号可以用来检测一个进程的健康状态,如果进程是健康状态,那么将会返回状态码0,否则将会返回1。
2、在 keepalived 的配置文件中使用 vrrp_script 块来周期性的调用这个脚本:
vrrp_script check_nginx
{
script "/scripts/check_nginx.sh"
interval 2
}
3、在对应 vrrp_instance 块中使用 track_script 块启用上面定义的 vrrp_script 块:
track_script {
check_nginx
}
这里我就不演示 Nginx 的配置及启动效果啦~~重点是要理解上述内容的含义。
评论区