-de8bd8f33c3e44a59907dafe1884f228.png)




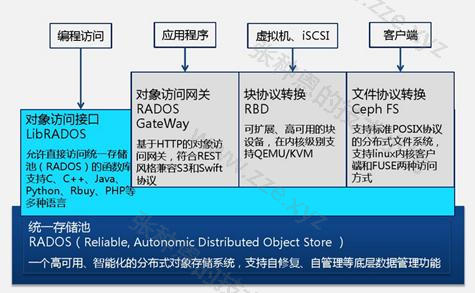
Ceph 是一个开源的分布式存储系统,同时支持对象存储、块设备、文件系统。
Ceph 是一个对象(object)式存储系统,它把每一个待管理的数据流(文件等数据)切分为一到多个固定大小(默认 4MB)的对象数据,并以其为原子单元(原子是构成元素的最小单元)完成数据的读写。
对象数据的底层存储服务是由多个存储主机(host)组成的存储集群,该集群也被称之为 RADOS(reliable automatic distributed object store)存储集群,即可靠的、自动化的、分布式的对象存储系统。
librados 是 RADOS 存储集群的API,支持 C/C++/JAVA/python/ruby/php 等编程语言客户端。
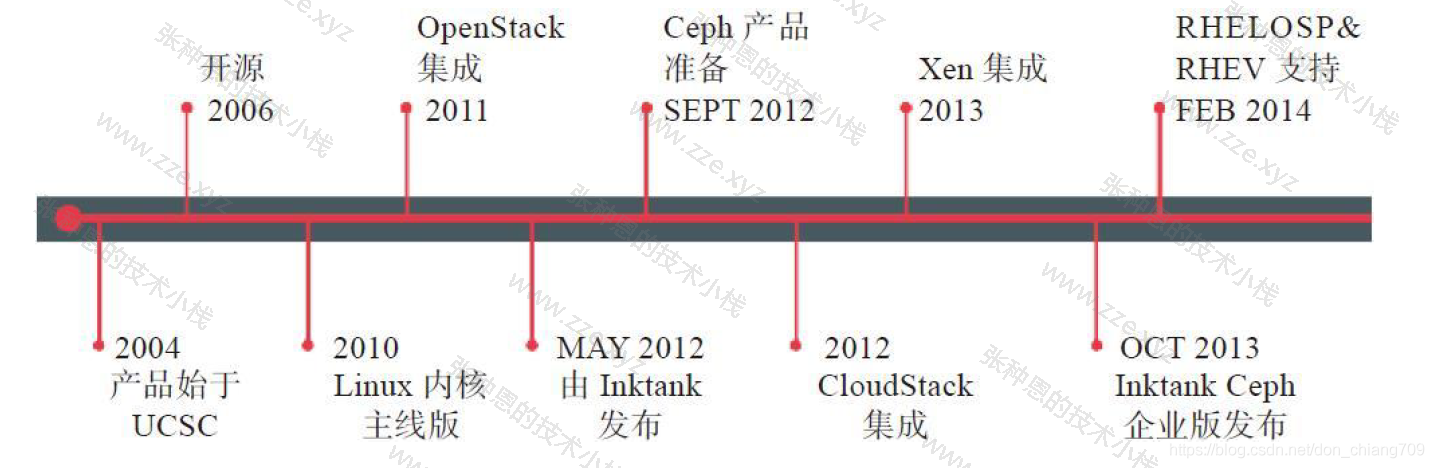
Ceph 历史
Ceph 项目起源于其创始人 Sage Weil 在加州大学 Santa Cruz 分校攻读博士期间的研究课题。项目的起始时间为 2004 年,在 2006 年基于开源协议开源了 Ceph 的源代码。Sage Weil 也相应成立了 Inktank 公司专注于 Ceph 的研发。在 2014 年 5 月,该公司被 Red Hat 收购。Ceph 项目的发展历程如下:
设计思想
Ceph 的设计旨在实现以下目标:
- 每一组件皆可扩展;
- 无单点故障;
- 基于软件(而非专用设备)并且开源(无供应商锁定);
- 在现有的廉价硬件上运行;
- 尽可能自动管理,减少用户干预;
版本历史
Ceph 的第一个版本是 0.1,发布日期为 2008 年 1 月,多年来 Ceph 的版本号一直采用递归更新的方式没变,直到 2015 年 4 月 0.94.1(Hammer 的第一个修正版)发布后,为了避免 0.99(以及 0.100 或 1.00),后期的命名方式发生了改变:
- x.0.z - 开发版,给早期测试者和勇士们;
- x.1.z - 候选版,用于测试集群、高手们;
- x.2.z - 稳定、修正版,给用户们;
x 将从 9 算起,它代表 Infernalis(首字母 l 是英文单词中的第九个字母),这样我们第九个发布周期的第一个开发版就是 9.0.0,后续的开发版依次是 9.0.0 -> 9.0.1 -> 9.0.2 等,测试版本就是 9.1.0 -> 9.1.1 -> 9.1.2,稳定版本就是 9.2.0 -> 9.2.1 -> 9.2.2。
Ceph 组成
不管你是想为云平台提供 Ceph 对象存储和/或 Ceph 块设备,还是想部署一个 Ceph 文件系统或者把 Ceph 作为他用,所有 Ceph 存储集群的部署都始于部署一个个 Ceph 节点、网络和 Ceph 存储集群。 Ceph 存储集群至少需要一个 Ceph Monitor 和两个 OSD 守护进程。而运行 Ceph 文件系统客户端时,则必须要有元数据服务器( Metadata Server )。

- Ceph OSDs:Ceph OSD 守护进程( Ceph OSD )的功能是存储数据,处理数据的复制、恢复、回填、再均衡,并通过检查其他 OSD 守护进程的心跳来向 Ceph Monitors 提供一些监控信息。当 Ceph 存储集群设定为有 2 个副本时,至少需要 2 个 OSD 守护进程,集群才能达到 active+clean 状态(Ceph 默认有 3 个副本,但你可以调整副本数)。
- Monitors:Ceph Monitor维护着展示集群状态的各种图表,包括监视器图、 OSD 图、归置组( PG )图、和 CRUSH 图。 Ceph 保存着发生在Monitors 、 OSD 和 PG上的每一次状态变更的历史信息(称为 epoch )。
- MDS:Ceph 元数据服务器( MDS )为 Ceph 文件系统存储元数据(也就是说,Ceph 块设备和 Ceph 对象存储不使用 MDS )。元数据服务器使得 POSIX 文件系统的用户们,可以在不对 Ceph 存储集群造成负担的前提下,执行诸如 ls、find 等基本命令。
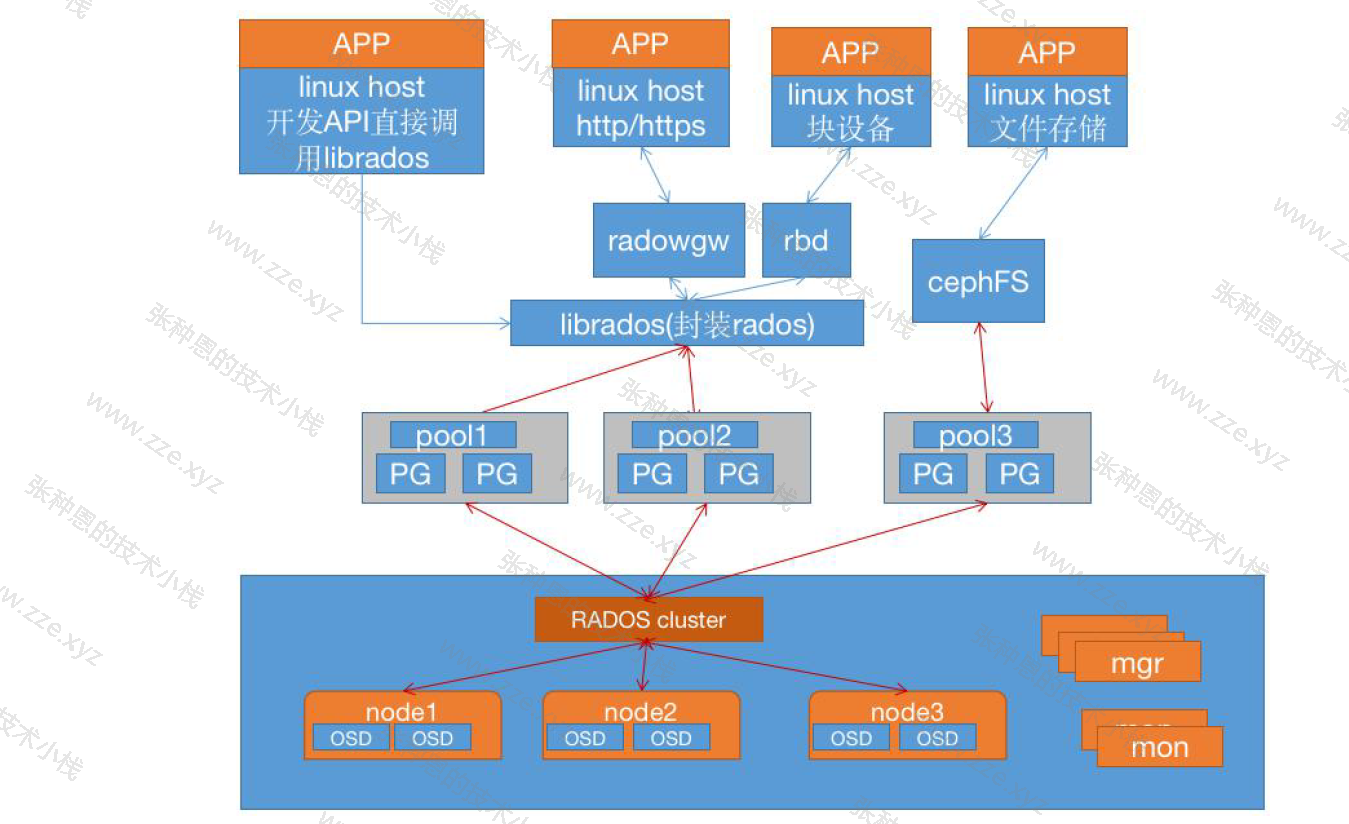
一个 Ceph 集群的组成部分:
- 若干的 Ceph OSD(对象存储守护程序);
- 至少需要一个 Ceph Monitors 监视器(奇数个,1,3,5,7...);
- 两个或以上的 Ceph 管理器,运行 Ceph 文件系统客户端时,还需要高可用的 CephMetadata Server(文件系统元数据服务器);
- RADOS cluster:由多台 host 存储服务器组成的 Ceph 集群;
- OSD(Object Storage Daemon):每台存储服务器的磁盘组成的存储空间;
- Mon(Monitor):Ceph 的监视器,维护 OSD 和 PG 的集群状,一个 Ceph 集群至少要有一个 Mon,可以是一三五七等等这样的奇数个;
- Mgr(Manager):负责跟踪运行时指标和 Ceph 集群的当前状态,包括存储利用率,当前性能指标和系统负载等;
集群角色
Monitor(ceph-mon) ceph 监视器
在一个主机上运行的一个守护进程,用于维护集群状态映射(maintains maps of thecluster state),比如 Ceph 集群中有多少存储池、每个存储池有多少 PG 以及存储池和 PG 的映射关系等,monitor map,manager map,the OSD map,the MDS map,and the CRUSH map,这些映射是 Ceph 守护程序相互协调所需的关键群集状态,此外监视器还负责管理守护程序和客户端之间的身份验证(认证使用 cephX 协议),包括有关 Monitor 节点端到端的信息,其中包括 Ceph 集群 ID,监控主机名和 IP 以及端口。并且存储当前版本信息以及最新更改信息,通过 ceph mon dump 查看 Monitor map。通常至少需要三个监视器才能实现冗余和高可用性。
Managers(ceph-mgr) 管理器
在一个主机上运行的一个守护进程,Ceph Manager 守护程序(ceph-mgr)负责跟踪运行时指标和 Ceph 集群的当前状态,包括存储利用率,当前性能指标和系统负载.CephManager 守护程序还托管基于 python 的模块来管理和公开 Ceph 集群信息,包括基于 Web 的 Ceph 仪表板和 REST API。高可用性通常至少需要两个管理器。
Ceph OSDs(ceph-osd) 对象存储守护程序
即对象存储守护程序,但是它并非针对对象存储。是物理磁盘驱动器,将数据以对象的形式存储到集群中的每个节点的物理磁盘上。OSD 负责存储数据、处理数据复制、恢复、回(Backfilling)、再平衡。完成存储数据的工作绝大多数是由 OSD daemon 进程实现。在构建 Ceph OSD 的时候,建议采用 SSD 磁盘以及 xfs 文件系统来格式化分区。此外 OSD 还对其它 OSD 进行心跳检测,检测结果汇报给 Monitor。通常至少需要 3 个 Ceph OSD 才能实现冗余和高可用性。
ceph-osd 进程每隔 6 秒向 ceph-mon 进程(3300 端口)汇报状态,ceph-mon 进程如在 20 秒后未接收到对应 ceph-osd 进程的状态上报则会认为对应的 OSD 已经挂了,然后会发起新的选举流程来添加新的 OSD 到对应 PG 来顶替挂掉的 OSD。
MDS(ceph-mds) 元数据服务器
为 Ceph 文件系统(NFS/CIFS)存储元数据,即 Ceph 块设备和 Ceph 对象存储不使用 MDS。
Ceph 管理节点
Ceph 的常用管理接口是一组命令行工具程序,例如 rados、ceph、rbd 等命令,Ceph 管理员可以从某个特定的 ceph-mon 节点执行管理操作。
推荐使用部署专用的管理节点对 Ceph 进行配置管理、升级与后期维护,方便后期权限管理,管理节点的权限只对管理人员开放,可以避免一些不必要的误操作的发生。
名词术语
RADOS
Reliable Autonomic Distributed Object Store,即可靠的、自动化的、分布式的对象存储系统。RADOS 是 Ceph 存储集群的基础。在 Ceph 中,所有数据都以对象的形式存储,并且无论什么数据类型,RADOS 对象存储都将负责保存这些对象。
librados
librados 库,为应用程度提供访问接口。同时也为块存储、对象存储、文件系统提供原生的接口。
RADOSGW
网关接口,提供对象存储服务。它使用 librgw 和 librados 来实现允许应用程序与 Ceph 对象存储建立连接。并且提供 S3 和 Swift 兼容的 RESTful API 接口。
CephFS
Ceph 文件系统,与 POSIX 兼容的文件系统,基于 librados 封装原生接口。
RBD
块设备,它能够自动精简配置并可调整大小,而且将数据分散存储在多个 OSD 上。
CRUSH
CRUSH,Controlled Replication Under Scalable Hashing,它表示可控的、可复制的、可伸缩的一致性 hash 算法,Ceph 的高性能/高可用就是采用这种算法实现。CRUSH 算法取代了元数据表,它通过计算系统中数据来得到目标文件应该被写入或读出的位置。CRUSH 能够感知基础架构,能够理解基础设施各个部件之间的关系。
Ceph 使用 CURSH 算法来存放和管理数据,它是 Ceph 的智能数据分发机制。Ceph 使用 CRUSH 算法来准确计算数据应该被保存到哪里,以及应该从哪里读取,和保存元数据不同的是,CRUSH 按需计算出元数据,因此它就消除了对中心式的服务器/网关的需求,它使得 Ceph 客户端能够计算出元数据,该过程也称为 CRUSH 查找,然后和 OSD 直接通信。
- 如果是把对象直接映射到 OSD 之上会导致对象与 OSD 的对应关系过于紧密和耦合,当 OSD 由于故障发生变更时将会对整个 Ceph 集群产生影响;
- 于是 Ceph 将一个对象映射到 RADOS 集群的时候分为两步走:首先使用一致性 hash 算法将对象映射到 PG,然后将 PG ID 基于 CRUSH 算法映射到 OSD 即可查到对象;
- 以上两个过程都是以"实时计算"的方式完成,而没有使用传统的查询数据与块设备的对应表的方式,这样有效避免了组件的中心化问题,也解决了查询性能和冗余问题,使得 Ceph 集群扩展不再受查询的性能限制;
逻辑组织架构
Pool:存储池、分区,存储池的大小取决于底层的存储空间;
PG(placement group):一个 Pool 内部可以有多个 PG 存在,Pool 和 PG 都是抽象的逻辑概念,一个 Pool 中有多少个 PG 可以通过公式计算;
OSD(Object Storage Daemon,对象存储设备):每一块磁盘都是一个 OSD,一个主机由一个或多个 OSD 组成;
Ceph 集群部署好之后,要先创建存储池才能向 Ceph 写入数据,文件在向 Ceph 保存之前要先进行一致性 hash 计算,计算后会把文件保存在某个对应的 PG,此文件一定属于某个 Pool 的一个 PG,再通过 PG 保存在 OSD 上。
数据对象在写到主 OSD 之后再同步到从 OSD 以实现数据的高可用。
存储文件过程
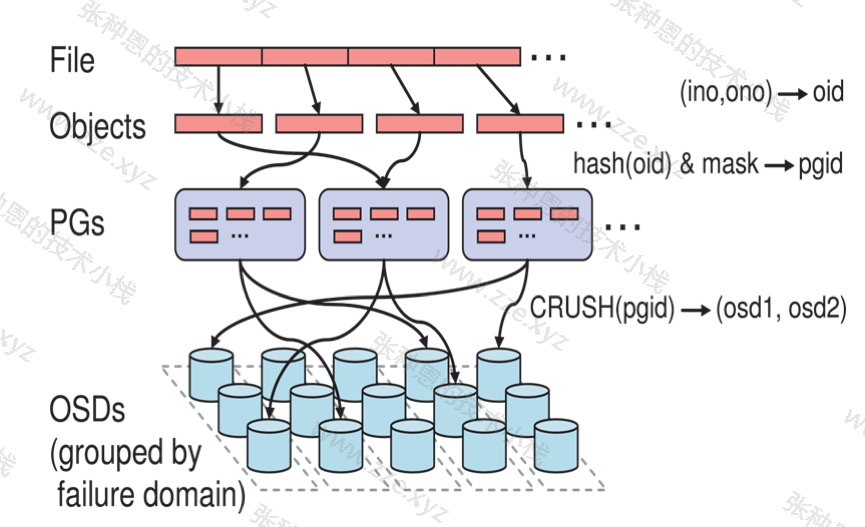
首先用户把一个文件放到 Ceph 集群后,先把文件进行分割,分割为等大小的小块,小块叫 Object,然后这些小块跟据一定算法(哈希算法)跟规律放置到 PG 组里,就是归置组,然后再把归置组映射到 OSD。
无论使用哪种存储方式(对象、块、文件系统),存储的数据都会被切分成 Objects。Objects size 大小可以由管理员调整,通常为 2M 或 4M。每个 Object 都会有一个唯一的 OID,由 ino 与 ono 生成,虽然这些名词看上去很复杂,其实相当简单。
- ino:即是文件的 File ID,用于在全局唯一标识每一个文件;
- ono:则是分片的编号;
比如:一个文件 FileID 为 A,它被切成了两个 Object,一个 Object 编号 0,另一个编号为 1,那么这两个文件的 oid 则为 A0 与 A1 。
File:此处的 File 就是用户需要存储或者访问的文件。对于一个基于 Ceph 开发的对象存储应用而言,这个 File 也就对应于应用中的“对象”,也就是用户直接操作的“对象”。
Ojbect:此处的 Object 是 RADOS 所看到的“对象”。Object 与上面提到的 File 的区别是,Object 的最大大小由 RADOS 限定(通常为 2MB 或 4MB),以便实现底层存储的组织管理。因此,当上层应用向 RADOS 存入很大的 File 时,需要将 File 切分成统一大小的一系列 Object(最后一个的大小可以不同)进行存储。
PG(Placement Group):顾名思义,PG 的用途是对 Object 的存储进行组织和位置映射。具体而言,一个 PG 负责组织若干个 Object(可以为数千个甚至更多),但一个 Object 只能被映射到一个 PG 中,即,PG 和 Object 之间是“一对多”映射关系。同时,一个 PG 会被映射到 n 个 OSD 上,而每个 OSD 上都会承载大量的 PG,即,PG 和 OSD 之间是“多对多”映射关系。在实践当中,n 至少为 2,如果用于生产环境,则至少为 3。一个 OSD 上的 PG 则可达到数百个。事实上,PG 数量的设置牵扯到数据分布的均匀性问题。
OSD:即 object storage device,前文已经详细介绍,此处不再展开。唯一需要说明的是,OSD 的数量事实上也关系到系统的数据分布均匀性,因此其数量不应太少。在实践当中,至少也应该是数十上百个的量级才有助于 Ceph 系统的设计发挥其应有的优势。
基于上述定义,便可以对寻址流程进行解释了。具体而言, Ceph 中的寻址至少要经历以下三次映射:
- File 到切分后的 Object 映射;
- Object 到 PG 的映射(hash(oid) & mask -> pgid);
- PG 到 OSD 映射(通常是多个 OSD),通过 CRUSH 算法;
伪代码流程:
locator = object_name
obj_hash = hash(locator)
pg = obj_hash % num_pg
osds_for_pg = crush(pg) # returns a list of osds
primary = osds_for_pg[0]
replicas = osds_for_pg[1:]
RADOS 分布式存储相较于传统分布式存储的优势在于:
- 将文件映射到 Object 后,利用 Cluster Map 通过 CRUSH 计算而不是查找表方式定位文件数据存储到存储设备的具体位置。优化了传统文件到块的映射和Block Map 的管理;
- RADOS 充分利用 OSD 的智能特点,将部分任务授权给 OSD,最大程度地实现可扩展;
元数据保存方式
Ceph 对象数据的元数据信息放在哪里呢?对象数据的元数据以 key-value 的形式存在,在 RADOS 中有两种实现:xattrs 和 omap。
Ceph 可选后端支持多种存储引擎,比如 filestore、bluestore、kvstore、memstore,ceph 使用 bluestore 存储对象数据的元数据信息。
xattrs 扩展属性
是将元数据保存在对象对应文件的扩展属性中并保存到系统磁盘上,这要求支持对象存储的本地文件系统(一般是 XFS)支持扩展属性。
omap(object-map) 对象映射
omap 是 object map 的简称,是将元数据保存在本地文件系统之外的独立 key-value 存储系统中,在使用 FileStore 时是 Leveldb,在使用 BlueStore 时是 RocksDB,由于 FileStore 存在功能问题(需要将磁盘格式化为 XFS 格式)及元数据高可用问题等问题,因此在目前 Ceph 主要使用 BlueStore。
FileStore 与 LevelDB
Ceph 早期基于 FileStore 使用 google 的 LeveIDB 保存对象的元数据,LevelDb 是一个持久化存储的 KV 系统,和 Redis 这种内存型的 KV 系统不同,LevelDB 不会像 Redis 一样将数据放在内存从而占用大量的内存空间,而是将大部分数据存储到磁盘上,但是需要把磁盘上的 Leveldb 空间格式化为文件系统(XFS)。
FileStore 将数据保存到与 Posix 兼容的文件系统(例如 Btrfs、XFS、Ext4),在 Ceph 后端使用传统的 Linux 文件系统尽管提供了一些好处,但也有代价,如性能、对象属性与磁盘本地文件系统属性匹配存在限制等。
BlueStore 与 RocksDB
由于 LevelDB 依然需要需要磁盘文件系统的支持,后期 facebok 对 LevelDB 进行改进为 RocksDB,将对象的元数据保存在 RocksDB,但是 RocksDB 的数据又放在哪里呢?放在内存怕丢失,放在本地磁盘但是解决不了高可用。
Ceph 对象数据放在了每个 OSD 中,那么就在当前 OSD 中划分出一部分空间,格式化为 BlueFS 文件系统用于 RocksDB 保存对象中的元数据信息(称为 BlueStore),并实现元数据的高可用,BlueStore 最大的特点是构建在裸磁盘设备之上,并且对诸如 SSD 等新的存储设备做了很多优化工作:
- 对全 SSD 及全 NVME SSD 闪存适配;
- 绕过本地文件系统层,直接管理裸设备,缩短 IO 路径;
- 严格分离元数据和数据,提高索引效率;
- 使用 KV 索引,解决文件系统目录结构遍历效率低的问题;
- 支持多种设备类型,解决日志“双写”问题;
- 期望带来至少 2 倍的写性能提升和同等读性能;
- 增加数据校验及数据压缩等功能;
RocksDB 通过中间层 BlueRocksEnv 访问文件系统的接口,这个文件系统与传统的 Linux 文件系统(例如 Ext4 和 XFS)是不同的,它不是在 VFS 下面的通用文件系统,而是一个用户态的逻辑。BlueFS 通过函数接口(API,非 POSIX)的方式为 BlueRocksEnv 提供类似文件系统的能力。
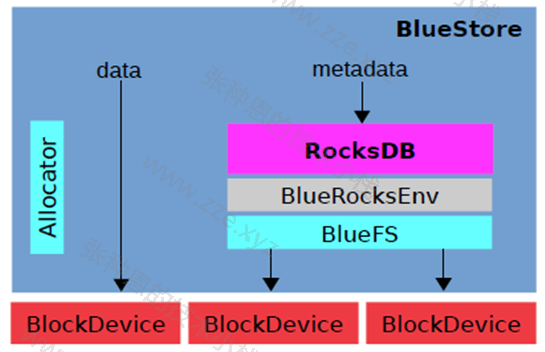
BlueStore 的逻辑架构如上图所示,模块的划分都还比较清晰,我们来看下各模块的作用:
- Allocator:负责裸设备的空间管理分配;
- RocksDB:RocksDB 是 facebook 基于 LevelDB 开发的一款 kv 数据库,BlueStore 将元数据全部存放至 RocksDB 中,这些元数据包括存储预写式日志、数据对象元数据,Ceph 的 omap 数据信息、以及分配器的元数据;
- BlueRocksEnv:这是 RocksDB 与 BlueFS 交互的接口。RocksDB 提供了文件操作的接口 EnvWrapper(Env 封装器),可以通过继承实现该接口来自定义底层的读写操作,BlueRocksEnv 就是继承自 EnvWrapper 实现对 BlueFS 的读写;
- BlueFS:BlueFS 是 BlueStore 针对 RocksDB 开发的轻量级文件系统,用于存放 RocksDB 产生的 .sst 和 .log 等文件;
- BlockDecive:BlueStore 抛弃了传统的 ext4、xfs 文件系统,使用直接管理裸盘的方式;
相关链接:
评论区