-de8bd8f33c3e44a59907dafe1884f228.png)




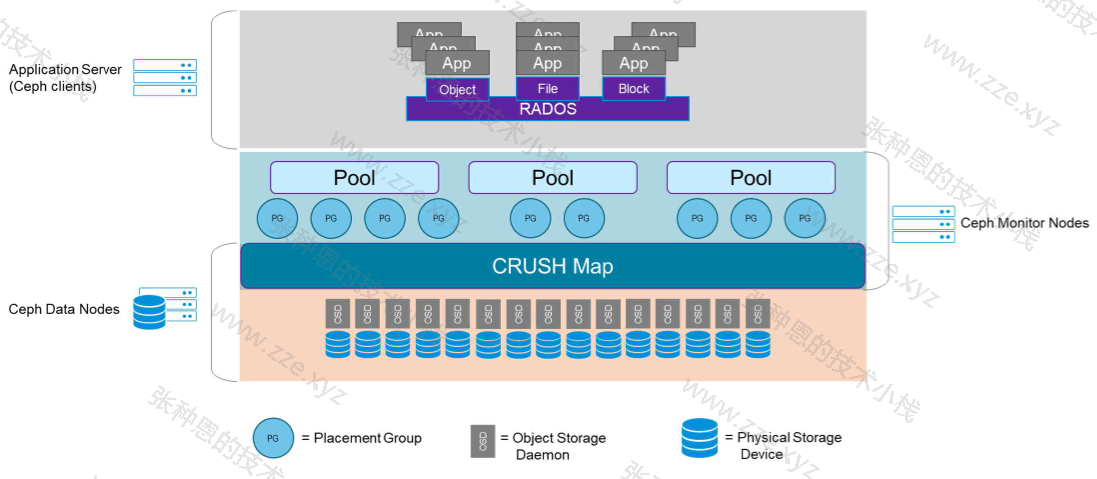
块设备 RBD
RBD(RADOS Block Devices)为块存储的一种,RBD 通过 librbd 库与 OSD 进行交互,RBD 为 KVM 等虚拟化技术和云服务(如 OpenStack 和 CloudStack)提供高性能和无限可扩展性的存储后端。这些系统依赖于 libvirt 和 QEMU 应用程序与 RBD 进行集成。客户端基于 librbd 库即可将 RADOS 存储集群用作块设备,不过,用于 RBD 的存储池需要事先启用 RBD 功能并进行初始化。
初始化 RBD 存储池
下面的命令创建一个名为 myrbd1 的存储池,并在启用 RBD 功能后对其进行初始化:
# 创建存储池
$ ceph osd pool create myrbd1 64 64
pool 'myrbd1' created
# 启用 RBD 功能
$ ceph osd pool application enable myrbd1 rbd
enabled application 'rbd' on pool 'myrbd1'
# 通过 rbd 命令对 RBD 存储池进行初始化
$ rbd pool init -p myrbd1
创建并验证映像
不过,rbd 存储池并不能直接用于块设备,而是需要事先在其中按需创建映像(image),并把映像文件作为块设备使用,rbd 命令可用于创建、查看及删除块设备相应的映像(image),以及克隆映像、创建快照、将映像回滚到快照和查看快照等管理操作。
例如,下面的命令能够创建一个大小为 5G 名为 myimg1 的映像:
$ rbd create myimg1 --size 5G --pool myrbd1
上述是以默认方式创建的 myimg1 映像,也可在创建映像时指定映像特性,以创建名为 myimg2 的映像为例:
# 除了 layering 特性,其它的特性需要高版本内核支持
$ rbd create myimg2 --size 1G --pool myrbd1 --image-format 2 --image-feature layering
默认方式创建的映像包含很多特性,部分特性对挂载映像的宿主机内核版本有要求,所以会导致有些系统的内核版本比较低是就无法挂载使用,所以我们通常使用创建 myimg2 映像这种方式来仅启用部分特性。
特性简介:
- layering:支持镜像分层快照特性,用于快照及写时复制,可以对 image 创建快照并保护,然后从快照克隆出新的 image 出来,父子 image 之间采用 COW 技术,共享对象数据;
- striping:支持条带化 v2,类似 raid 0,只不过在 Ceph 环境中的数据被分散到不同的对象中、可改善顺序读写场景较多情况下的性能;
- exclusive-lock:支持独占锁,限制一个镜像只能被一个客户端使用;
- object-map:支持对象映射(依赖 exclusive-lock),加速数据导入导出及已用空间统计等,此特性开启的时候,会记录 image 所有对象的一个位图,用以标记对象是否真的存在,在一些场景下可以加速 IO;
- fast-diff:快速计算镜像与快照数据差异对比(依赖 object-map);
- deep-flatten:支持快照扁平化操作,用于快照管理时解决快照依赖关系等;
- journaling:修改数据是否记录日志,该特性可以通过记录日志并通过日志恢复数据(依赖独占锁),开启此特性会增加系统磁盘 IO 使用;
默认开启的特性有:layering、exclusive-lock、object-map、fast-diff、deep-flatten。
查看指定存储池中的所有映像:
$ rbd ls --pool myrbd1
myimg1
myimg2
查看指定映像的信息:
$ rbd --image myimg1 --pool myrbd1 info
rbd image 'myimg1':
size 5 GiB in 1280 objects
order 22 (4 MiB objects)
snapshot_count: 0
id: 5e3ddfe68b5c
block_name_prefix: rbd_data.5e3ddfe68b5c
format: 2
features: layering, exclusive-lock, object-map, fast-diff, deep-flatten
op_features:
flags:
create_timestamp: Wed Sep 15 07:40:08 2021
access_timestamp: Wed Sep 15 07:40:08 2021
modify_timestamp: Wed Sep 15 07:40:08 2021
$ rbd --image myimg2 --pool myrbd1 info
rbd image 'myimg2':
size 1 GiB in 256 objects
order 22 (4 MiB objects)
snapshot_count: 0
id: 11b21c607ce7
block_name_prefix: rbd_data.11b21c607ce7
format: 2
features: layering
op_features:
flags:
create_timestamp: Wed Sep 15 07:43:26 2021
access_timestamp: Wed Sep 15 07:43:26 2021
modify_timestamp: Wed Sep 15 07:43:26 2021
客户端挂载使用
映像创建好后就可以挂载使用了,而挂载映像的主机也就是客户端必须安装 ceph-common 包才能执行挂载操作。
安装 ceph-common
CentOS 7
# 添加 epel 源
$ wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
# 添加 ceph 源
$ rpm -ivh https://mirrors.tuna.tsinghua.edu.cn/ceph/rpm-15.2.9/el7/noarch/ceph-release-1-1.el7.noarch.rpm
# 查看提供的包版本
$ yum list ceph-common --showduplicates
Loaded plugins: fastestmirror
Loading mirror speeds from cached hostfile
* base: mirrors.aliyun.com
* extras: mirrors.aliyun.com
* updates: mirrors.aliyun.com
Available Packages
ceph-common.x86_64 1:10.2.5-4.el7 base
ceph-common.x86_64 2:15.2.14-0.el7 Ceph
# 安装指定版本的 ceph-common 包
$ yum install ceph-common-15.2.14-0.el7 -y
当前时间(2021.9.15)官方并没有为 CentOS 7 提供最新版
16.2.5 - Pacific的ceph-common包,所以只能装版本为15.2.x - Octopus的ceph-common。所以在涉及到 Ceph 相关的服务时最好还是选 Debian 系的系统。
Ubuntu 18.04
# 添加 Ceph 源
$ wget -q -O- 'https://download.ceph.com/keys/release.asc' | sudo apt-key add -
$ sudo apt-add-repository 'deb https://mirrors.tuna.tsinghua.edu.cn/ceph/debian-pacific/ bionic main'
$ apt update
# 查看提供的包版本
$ apt-cache madison ceph-common
ceph-common | 16.2.5-1bionic | https://mirrors.tuna.tsinghua.edu.cn/ceph/debian-pacific bionic/main amd64 Packages
ceph-common | 12.2.13-0ubuntu0.18.04.8 | http://mirrors.aliyun.com/ubuntu bionic-updates/main amd64 Packages
ceph-common | 12.2.13-0ubuntu0.18.04.4 | http://mirrors.aliyun.com/ubuntu bionic-security/main amd64 Packages
ceph-common | 12.2.4-0ubuntu1 | http://mirrors.aliyun.com/ubuntu bionic/main amd64 Packages
ceph | 12.2.4-0ubuntu1 | http://mirrors.aliyun.com/ubuntu bionic/main Sources
ceph | 12.2.13-0ubuntu0.18.04.4 | http://mirrors.aliyun.com/ubuntu bionic-security/main Sources
ceph | 12.2.13-0ubuntu0.18.04.8 | http://mirrors.aliyun.com/ubuntu bionic-updates/main Sources
# 安装指定版本的 ceph-common 包
$ apt install ceph-common=16.2.5-1bionic -y
配置客户端认证
将部署 Ceph 集群时生成的 ceph.conf、ceph.client.admin.keyring 拷贝到客户端主机的 /etc/ceph 目录下:
# 我这里客户端 IP 为 172.20.0.5
$ scp ceph.conf ceph.client.admin.keyring root@172.20.0.5:/etc/ceph/
映射、格式化、挂载
在客户端映射映像到本地:
$ rbd --pool myrbd1 map myimg2
/dev/rbd0
$ lsblk | grep rbd0
rbd0 252:0 0 1G 0 disk
如上将 myrbd1 池中的 myimg2 映像映射到了客户端的 /dev/rbd0 设备,此时客户端就可以像使用普通硬盘设备一样来使用 /dev/rbd0 设备了。
格式化并挂载 /dev/rdb0 设备:
# 格式化
$ mkfs.xfs /dev/rbd0
Discarding blocks...Done.
meta-data=/dev/rbd0 isize=512 agcount=8, agsize=32768 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=0, sparse=0
data = bsize=4096 blocks=262144, imaxpct=25
= sunit=1024 swidth=1024 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal log bsize=4096 blocks=2560, version=2
= sectsz=512 sunit=8 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
# 挂载到目录
$ mount /dev/rbd0 /mnt
# 查看容量
$ df -h | grep rbd0
/dev/rbd0 1014M 33M 982M 4% /mnt
如果此时你试着挂载 myimg1 映像你会发现挂载失败:
$ rbd --pool myrbd1 map myimg1
rbd: sysfs write failed
RBD image feature set mismatch. You can disable features unsupported by the kernel with "rbd feature disable myrbd1/myimg1 object-map fast-diff deep-flatten".
In some cases useful info is found in syslog - try "dmesg | tail".
rbd: map failed: (6) No such device or address
这就是因为客户端主机的内核不支持 myimg1 的相应特性,可以按提示执行命令将几个不支持的特性关闭,然后再进行映射到本地操作:
$ rbd feature disable myrbd1/myimg1 object-map fast-diff deep-flatten
$ rbd --pool myrbd1 map myimg1
/dev/rbd1
普通用户挂载
在上面的挂载使用案例中我们是直接使用 admin 用户来挂载使用 RBD 的,但在实际生产使用时我们常常来创建一个拥有对指定存储池有读写权限的用户进行挂载使用,对于 Ceph 用户的管理可以先参考【Ceph 管理操作 - 认证机制 - 用户管理】。
# 在 Ceph 管理节点创建用户
$ ceph auth add client.zze mon 'allow r' osd 'allow rwx pool myrbd1'
# 生成普通用户的 keyring 文件
$ ceph-authtool --create-keyring ceph.client.zze.keyring
$ ceph auth get client.zze -o ceph.client.zze.keyring
# 拷贝到客户端
$ scp /etc/ceph/ceph.conf ceph.client.zze.keyring root@172.20.0.5:/etc/ceph/
# 客户端通过 client.zze 用户查看集群状态
$ ceph --user zze -s
# 客户端执行映射操作
$ rbd --user zze --pool myrbd1 map myimg1
扩容映像
将 myrbd1 池中的 myimg2 映像扩容到 10G:
$ rbd -p myrbd1 ls -l
NAME SIZE PARENT FMT PROT LOCK
myimg1 5 GiB 2 excl
myimg2 1 GiB 2
$ rbd resize --pool myrbd1 --image myimg2 --size 10G
$ rbd -p myrbd1 ls -l
NAME SIZE PARENT FMT PROT LOCK
myimg1 5 GiB 2 excl
myimg2 10 GiB 2
我测试了在客户端将映像分别格式化为 xfs 和 ext4 文件系统,挂载再进行扩容后:
- xfs:在执行了
xfs_growfs /dev/rbd0后可以直击识别到新增的容量; - ext4:在执行了
resize2fs /dev/rbd0后可以直接识别到新增的容量;
卸载映像
卸载指的是从客户端上取消 RBD 映像到本地设备的映射。
# 查看已映射的映像
$ rbd --user zze showmapped
id pool namespace image snap device
0 myrbd1 myimg1 - /dev/rbd0
# 取消映射
$ rbd --user zze -p myrbd1 unmap myimg1
删除映像
- 彻底删除
映像删除后数据也会被删除而且是无法恢复,因此在执行删除操作的时候要慎重。
# 在 Ceph 集群管理节点上操作,以删除 myrbd1 存储池的 myimg1 映像为例
$ rbd rm --pool myrbd1 --image myimg1
- 回收站
直接删除的映像无法恢复,但是还有另一种方法可以先把映像移动到回收站,后续确认后再从回收站彻底删除。
# 查看映像当前有没有客户端在使用
$ rbd status --pool myrbd1 --image myimg1
# 移动映像到回收站
$ rbd trash move --pool myrbd1 --image myimg1
# 查看回收站中的映像
$ rbd trash list --pool myrbd1
11b21c607ce7 myimg1
# 从回收站还原,将回收站中 id 为 11b21c607ce7 的映像还原到名为 myimg1 的映像
$ rbd trash restore --pool myrbd1 --image myimg1 --image-id 11b21c607ce7
# 从回收站删除映像
$ rbd trash remove --pool myrbd1 --image-id 11b21c607ce7
映像快照
映像的快照管理是它能够给 rbd 的 snap 子命令来完成的,常用操作有如下:
snap create # 创建快照
snap limit clear # 清除映像的快照数量限制
snap limit set # 设置一个映像的快照上限
snap list # 列出快照
snap protect # 保护快照不被删除
snap purge # 删除所有未被保护的快照
snap remove # 删除一个快照
snap rename # 重命名快照
snap rollback # 还原快照
snap unprotect # 取消快照保护
例:
# 为 myrbd1 存储池中的 myimg1 映像创建一个名为 myimg1-20210929 的快照
$ rbd snap create --pool myrbd1 --image myimg1 --snap myimg1-20210929
# 列出 myrbd1 存储池中 myimg1 映像的快照
$ rbd snap list --pool myrbd1 --image myimg1
SNAPID NAME SIZE PROTECTED TIMESTAMP
4 myimg1-20210929 5 GiB Wed Sep 29 07:09:40 2021
# 将 myrbd1 存储池中的 myimg1 映像还原到名为 myimg1-20210929 的快照
$ rbd snap rollback --pool myrbd1 --image myimg1 --snap myimg1-20210929
# 删除 myrbd1 存储池中的 myimg1 映像的名为 myimg1-20210929 的快照
$ rbd snap remove --pool myrbd1 --image myimg1 --snap myimg1-20210929
# 设置 myrbd1 存储池中的 myimg1 映像的快照数量最多为 5 个
$ rbd snap limit set --pool myrbd1 --image myimg1 --limit 5
对象存储 RGW
RGW(ceph radosgw)提供的是 REST 接口,客户端通过 http 与其进行交互,完成数据的增删改查等管理操作。
radosgw 用在需要使用 RESTful API 接口访问 Ceph 数据的场合,因此在使用 RBD 即块存储得场合或者使用 CephFS 的场合可以不用启用 radosgw 功能。
如果是在使用 radosgw 的场合,则需要在 ceph-mgr 服务器上执行以下命令将 ceph-mgr 服务器部署为 RGW 主机:
# 安装 ceph-mgr 相关软件包
$ apt-cache madison radosgw
radosgw | 16.2.5-1bionic | https://mirrors.tuna.tsinghua.edu.cn/ceph/debian-pacific bionic/main amd64 Packages
radosgw | 12.2.13-0ubuntu0.18.04.8 | http://mirrors.aliyun.com/ubuntu bionic-updates/main amd64 Packages
radosgw | 12.2.13-0ubuntu0.18.04.4 | http://mirrors.aliyun.com/ubuntu bionic-security/main amd64 Packages
radosgw | 12.2.4-0ubuntu1 | http://mirrors.aliyun.com/ubuntu bionic/main amd64 Packages
ceph | 12.2.4-0ubuntu1 | http://mirrors.aliyun.com/ubuntu bionic/main Sources
ceph | 12.2.13-0ubuntu0.18.04.4 | http://mirrors.aliyun.com/ubuntu bionic-security/main Sources
ceph | 12.2.13-0ubuntu0.18.04.8 | http://mirrors.aliyun.com/ubuntu bionic-updates/main Sources
$ apt install radosgw=16.2.5-1bionic -y
在 Ceph 集群管理节点使用 ceph-deploy 启用 rgw 服务:
# 在 ceph-node1 上启用 rgw 服务
$ ceph-deploy --overwrite-conf rgw create ceph-node1
此时 ceph-node1 节点就会监听一个 7480 端口用来提供 radosgw 服务:
$ ss -tanlp | grep 7480
LISTEN 0 128 0.0.0.0:7480 0.0.0.0:* users:(("radosgw",pid=29992,fd=64))
LISTEN 0 128 [::]:7480 [::]:* users:(("radosgw",pid=29992,fd=65))
该端口提供的是 HTTP 服务,测试访问一下:
$ curl -I http://ceph-node1:7480
HTTP/1.1 200 OK
Transfer-Encoding: chunked
x-amz-request-id: tx000000000000000000003-006141bf77-1236-default
Content-Type: application/xml
Date: Wed, 15 Sep 2021 09:40:07 GMT
Connection: Keep-Alive
剩下的操作就是把 radosgw 服务的相关信息交给开发同志们让他们去敲代码对接 Ceph 的 Rest API 了。
如果要对 radosgw 服务做高可用,只需要多创建几个 radosgw 服务,然后在集群前端放一个 lb 代理到这几个 radosgw 服务即可。
文件存储 Ceph FS
Ceph FS 即 ceph filesystem,可以实现文件系统共享功能,客户端通过 Ceph 协议挂载并使用 Ceph 集群作为数据存储服务器。
Ceph FS 需要运行 Meta Data Services(MDS)服务,其守护进程为 ceph-mds,ceph-mds 进程管理与 Ceph FS 上存储的文件相关的元数据,并协调对 Ceph 存储集群的访问。
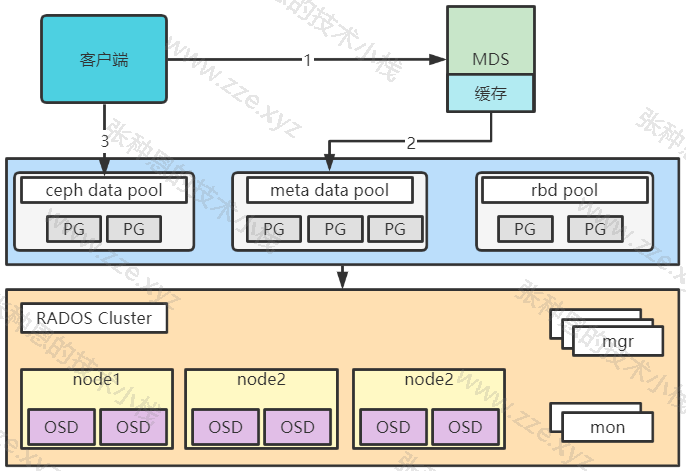
部署 MDS 服务
在指定的 ceph-mds 服务器部署 ceph-mds 服务,可以和其它服务器混用(如 ceph-mon,ceph-mgr)。
# 我这里在 ceph-node2 和 ceph-node3 上安装 ceph-mds 服务
$ apt-cache madison ceph-mds
ceph-mds | 16.2.5-1bionic | https://mirrors.tuna.tsinghua.edu.cn/ceph/debian-pacific bionic/main amd64 Packages
ceph-mds | 12.2.13-0ubuntu0.18.04.8 | http://mirrors.aliyun.com/ubuntu bionic-updates/universe amd64 Packages
ceph-mds | 12.2.13-0ubuntu0.18.04.4 | http://mirrors.aliyun.com/ubuntu bionic-security/universe amd64 Packages
ceph-mds | 12.2.4-0ubuntu1 | http://mirrors.aliyun.com/ubuntu bionic/universe amd64 Packages
ceph | 12.2.4-0ubuntu1 | http://mirrors.aliyun.com/ubuntu bionic/main Sources
ceph | 12.2.13-0ubuntu0.18.04.4 | http://mirrors.aliyun.com/ubuntu bionic-security/main Sources
ceph | 12.2.13-0ubuntu0.18.04.8 | http://mirrors.aliyun.com/ubuntu bionic-updates/main Sources
$ apt install ceph-mds=16.2.5-1bionic -y
在 Ceph 集群管理节点上添加 ceph-mds 节点到集群:
$ ceph-deploy mds create ceph-node2 ceph-node3
验证 ceph-mds 服务:
$ ceph mds stat
2 up:standby
上述输出的含义是现在有 2 个 ceph-mds 服务是已启动但都是备选状态,这是因为 Ceph FS 在使用之前需要指定两个存储池,一个用来存放元数据,一个用来存放数据。
创建存储池和文件系统
使用 Ceph FS 前需要事先创建一个文件系统,并为其分别指定元数据和数据相关的存储池,如下命令将创建名为 mycephfs 的文件系统,它使用 cephfs-metadata 作为元数据存储池,使用 cephfs-data 作为数据存储池。
# 创建保存 metadata 的 pool
$ ceph osd pool create cephfs-metadata 32 32
pool 'cephfs-metadata' created
# 创建保存 data 的 pool
$ ceph osd pool create cephfs-data 64 64
pool 'cephfs-data' created
# 创建 mycephfs 文件系统
$ ceph fs new mycephfs cephfs-metadata cephfs-data
new fs with metadata pool 8 and data pool 9
再次查看 Ceph 集群状态和 ceph-mds 服务状态:
$ ceph -s
\ cluster:
id: 2a71ed03-5918-4126-a2ec-8fd8ac173627
health: HEALTH_OK
services:
mon: 3 daemons, quorum ceph-node1,ceph-node2,ceph-node3 (age 2h)
mgr: ceph-node1(active, since 45h), standbys: ceph-node2, ceph-node3
mds: 1/1 daemons up, 1 standby
osd: 9 osds: 9 up (since 30h), 9 in (since 43h)
rgw: 2 daemons active (2 hosts, 1 zones)
data:
volumes: 1/1 healthy
pools: 9 pools, 297 pgs
objects: 261 objects, 14 MiB
usage: 891 MiB used, 179 GiB / 180 GiB avail
pgs: 297 active+clean
io:
client: 1.3 KiB/s wr, 0 op/s rd, 4 op/s wr
$ ceph mds stat
mycephfs:1 {0=ceph-node3=up:active} 1 up:standby
可以看到 ceph-node3 上的 ceph-mds 服务已经成功激活了,当 ceph-node3 上的 ceph-mds 服务挂掉时会自动激活 ceph-node2 上的 ceph-mds 服务继续提供服务。
查看 mycephfs 文件系统的状态:
$ ceph fs status mycephfs
mycephfs - 0 clients
========
RANK STATE MDS ACTIVITY DNS INOS DIRS CAPS
0 active ceph-node2 Reqs: 0 /s 10 13 12 0
POOL TYPE USED AVAIL
cephfs-metadata metadata 96.0k 56.4G
cephfs-data data 0 56.4G
STANDBY MDS
ceph-node3
MDS version: ceph version 16.2.5 (0883bdea7337b95e4b611c768c0279868462204a) pacific (stable)
到这一步 Ceph FS 已经部署完毕了。此时在 mon 服务器上的 ceph-mon 服务会暴露一个 6789 端口来支持客户端对 Ceph FS 的访问:
$ ss -tanlp | grep 6789
LISTEN 0 128 172.20.0.23:6789 0.0.0.0:* users:(("ceph-mon",pid=29314,fd=27))
客户端挂载使用
找一台主机用作客户端来测试 Ceph FS 的挂载,需要指定 mon 节点的 6789 端口。
客户端挂载时需要通过 ceph-mon 服务的认证,所以必须使用一个有权限的秘钥,这里我们先直接用创建集群时生成的 admin 秘钥:
$ cat ceph.client.admin.keyring | grep key
key = AQB/dEBhQnxtKxAAy6XqHxa8ikfL1VbNAbzLDg==
客户端执行挂载操作(执行挂载操作客户端主机内核版本必须在 3.6.34 及以上):
# 172.20.0.21:6789,172.20.0.22:6789,172.20.0.23:6789 这三个地址对应我三个 mon 节点的 mon 服务地址
$ mount -t ceph 172.20.0.21:6789,172.20.0.22:6789,172.20.0.23:6789:/ /mnt -o name=admin,secret=AQB/dEBhQnxtKxAAy6XqHxa8ikfL1VbNAbzLDg==
$ df -h | grep mnt
172.20.0.21:6789,172.20.0.22:6789,172.20.0.23:6789:/ 57G 0 57G 0% /mnt
虽然客户端主机本身内核就支持挂载 Ceph FS,但是还是推荐在客户端主机装上
ceph-common包,ceph-common会提供一些更新更高效的机制去访问 Ceph FS。
普通用户挂载
创建普通用户来操作 Ceph FS:
# 创建名为 client.fs 的用户让其能够读写 ceph-data 池
$ ceph auth add client.fs mon 'allow r' mds 'allow rw' osd 'allow rwx pool=cephfs-data'
# 生成普通用户的 keyring 文件
$ ceph-authtool --create-keyring ceph.client.fs.keyring
$ ceph auth get client.fs -o ceph.client.fs.keyring
# 导出 key
$ ceph auth print-key client.fs > client.fs.key
# 拷贝到客户端
$ scp /etc/ceph/ceph.conf ceph.client.fs.keyring client.fs.key root@172.20.0.5:/etc/ceph/
客户端执行挂载操作:
# 客户端通过 client.fs 用户查看集群状态
$ ceph --user fs -s
# 172.20.0.21:6789,172.20.0.22:6789,172.20.0.23:6789 这三个地址对应我三个 mon 节点的 mon 服务地址
# 指定普通用户名和其 key 文件进行挂载
$ mount -t ceph 172.20.0.21:6789,172.20.0.22:6789,172.20.0.23:6789:/ /mnt -o name=fs,secretfile=/etc/ceph/client.fs.key
设置开机自动挂载:
$ vim /etc/fstab
172.20.0.21:6789,172.20.0.22:6789,172.20.0.23:6789:/ /mnt ceph defaults,name=fs,secretfile=/etc/ceph/client.fs.key,_netdev 0 0
用户空间挂载
上述挂载操作都是通过 mount 命令来执行的,该方式是在内核空间挂载,效率高。而在上面也有提到,只有 Linux 内核版本高于 2.6.34 时才可以直接使用 mount 命令来挂载 Ceph FS,那么如果客户端主机内核版本低于 2.6.34 或者说没有 ceph 内核模块那么此时就只能通过用户空间挂载了。
通过用户空间挂载的效率极低,所以不推荐使用。
要通过用户空间挂载 Ceph FS,需要在客户端主机安装上 ceph-fuse,以 CentOS 7 主机为例:
$ yum install epel-release -y
$ rpm -i https://mirrors.aliyun.com/ceph/rpm-octopus/el7/noarch/ceph-release-1-1.el7.noarch.rpm
$ yum install ceph-fuse ceph-common -y
执行挂载操作:
$ ceph-fuse --name client.fs -m 172.20.0.21:6789,172.20.0.22:6789,172.20.0.23:6789 /mnt
$ df -TH | grep mnt
ceph-fuse fuse.ceph-fuse 60G 0 60G 0% /mnt
设置开机自动挂载:
$ vim /etc/fstab
none /data fuse.ceph ceph.id=fs,ceph.conf=/etc/ceph/ceph.conf,_netdev,defaults 0 0
MDS 高可用
Ceph FS 的元数据使用的动态子树分区,把元数据划分名称空间对应到不同的 MDS,写入元数据的时候将元数据按照名称保存到不同主 MDS 上,有点类似于 Nginx 中的缓存目录分层。
Ceph MDS 作为 Ceph 的访问入口,需要实现高性能及数据备份。假设启动 4 个 MDS 进程,设置 2 个 Rank,这时候有 2 个 MDS 进程会分配给两个 Rank,还剩下 2 个 MDS 进程分别作为另外 2 个的备份.
设置每个 Rank 的备份 MDS,也就是如果此 Rank 当前的 MDS 出现问题马上切换到另个 MDS。设置备份的方法有很多,常用选项如下:
mds_standby_replay:值为true或false,true表示开启 replay 模式,这种模式下主 MDS 的信息将实时与从 MDS 同步,如果主宕机,从可以快速的切换,如果为false只有宕机的时候才去同步数据,这样会有一段时间的中断;mds_standby_for_name:设置当前 MDS 进程只用于备份于指定名称的 MDS;mds_standby_for_rank:设置当前 MDS 进程只用于备份于哪个 Rank;mds_standby_for_fscid:指定 Ceph FS 文件系统 ID,需要联合mds_standby_for_rank生效,如果设置mds_standby_for_rank,那么就是用于指定文件系统的指定 Rank,如果没有设置,就是指定文件系统的所有 Rank;
在上面部署 MDS 服务的过程中我们直接部署了两个 MDS 服务,一个主一个备:
$ ceph mds stat
mycephfs:1 {0=ceph-node2=up:active} 1 up:standby
为方便演示,我们再新增两个 MDS 节点:
$ ceph-deploy mds create ceph-node1 ceph-node4
$ ceph fs status
mycephfs - 1 clients
========
RANK STATE MDS ACTIVITY DNS INOS DIRS CAPS
0 active ceph-node2 Reqs: 0 /s 10 13 12 1
POOL TYPE USED AVAIL
cephfs-metadata metadata 172k 55.5G
cephfs-data data 0 55.5G
STANDBY MDS
ceph-node4
ceph-node3
ceph-node1
VERSION DAEMONS
ceph version 16.2.5 (0883bdea7337b95e4b611c768c0279868462204a) pacific (stable) ceph-node2, ceph-node3, ceph-node1, ceph-node4
查看 mycephfs 文件系统的配置:
$ ceph fs get mycephfs
Filesystem 'mycephfs' (1)
fs_name mycephfs
epoch 25
flags 12
created 2021-09-16T08:06:04.896047+0000
modified 2021-09-29T08:34:09.841292+0000
tableserver 0
root 0
session_timeout 60
session_autoclose 300
max_file_size 1099511627776
required_client_features {}
last_failure 0
last_failure_osd_epoch 235
compat compat={},rocompat={},incompat={1=base v0.20,2=client writeable ranges,3=default file layouts on dirs,4=dir inode in separate object,5=mds uses versioned encoding,6=dirfrag is stored in omap,7=mds uses inline data,8=no anchor table,9=file layout v2,10=snaprealm v2}
max_mds 1
in 0
up {0=34137}
failed
damaged
stopped
data_pools [9]
metadata_pool 8
inline_data disabled
balancer
standby_count_wanted 1
[mds.ceph-node2{0:34137} state up:active seq 26 addr [v2:172.20.0.22:6800/1759909574,v1:172.20.0.22:6801/1759909574]]
上述输出中 max_mds 1 表示当前集群中只能有一个主的 MDS。
- 设置处于激活状态 MDS 的数量
目前有四个 MDS 服务器,但是有一个主三个备,可以优化一下部署架构,设置为两主两备:
# 修改激活状态 MDS 的数量为 2
$ ceph fs set mycephfs max_mds 2
$ ceph mds stat
mycephfs:2 {0=ceph-node2=up:active,1=ceph-node1=up:active} 2 up:standby
目前 ceph-node3 和 ceph-node4 作为备,ceph-node1 和 ceph-node2 作为主,此时他们的主备关系是随机分配的,也就是说任何一个主宕机了,都可能由任何一个备顶上去。
我们可以控制一下主备关系,比如让 ceph-node3 只作为 ceph-node1 的备,ceph-node4 只作为 ceph-node2 的备。该功能需要修改 ceph.conf 实现,如下:
$ cat ceph.conf | grep mds -A 2
[mds.ceph-node3]
mds_standby_for_name = ceph-node1
mds_standby_replay = true
[mds.ceph-node4]
mds_standby_for_name = ceph-node2
mds_standby_replay = true
# 分发配置文件到各节点
$ ceph-deploy --overwrite-conf config push ceph-node1 ceph-node2 ceph-node3 ceph-node4
# 在各个节点重启 MDS 服务生效配置
$ systemctl restart ceph-mds@ceph-node1
$ systemctl restart ceph-mds@ceph-node2
$ systemctl restart ceph-mds@ceph-node3
$ systemctl restart ceph-mds@ceph-node4
导出为 NFS
可以通过 ganesha 让 Ceph FS 支持 NFS 协议共享使用,此种方式在你的客户端设备仅支持 NFS 协议时很有用。
在 Ceph 管理端安装并配置 ganesha:
# 安装包
$ apt install nfs-ganesha-ceph -y
# 修改配置
$ vim /etc/ganesha/ganesha.conf
NFS_CORE_PARAM {
Enable_NLM = false;
Enable_RQUOTA = false;
Protocols = 4;
}
EXPORT_DEFAULTS {
Access_Type = RW;
}
EXPORT {
Export_Id = 1;
Path = "/";
FSAL {
name = CEPH;
hostname = "172.20.0.21";
}
Squash = "No_root_squash";
Pseudo = "/zze";
SecType = "sys";
}
LOG {
Default_Log_Level = WARN;
}
# 重启生效
$ systemctl restart nfs-ganesha
客户端挂载:
$ mount -t nfs 172.20.0.21:/zze /mnt
$ df -TH | grep mnt
172.20.0.21:/zze nfs4 60G 0 60G 0% /mnt
评论区