-de8bd8f33c3e44a59907dafe1884f228.png)




介绍
事务 (transaction) 其实指的就是一组操作里面包含许多单一的逻辑,要么就是所有逻辑都成功 (提交),只要有一个逻辑没有成功,那么这一组操作就算失败,所有的数据都回归到最初的状态(回滚)。
MySQL 终端演示事务
现有如下账户表,有 id 为 1 和 2 的两个账户:
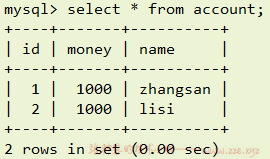
假如我们要让 id 为 1 的账户给 id 为 2 的账户转 100 块,我们要执行的 SQL 就是:
update account set money=money-100 where id=1;
update account set money=money+100 where id=2;
执行完之后:
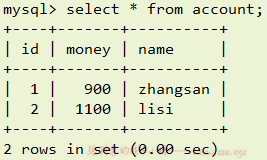
在上面示例中,其实 MySQL 默认就帮我们提交了事务,只是它把每一条执行的 SQL 语句当成了一组操作,也就是执行一条 SQL 事务就自动提交。
如果我们希望自己主动控制事务的提交,该怎么做呢?
方式一:关闭事务的自动提交
而 MySQL 事务的自动提交是可以通过 autocommit 变量设置的,查看该变量:

可以看到它默认是开启状态,现在我们将它关闭:

再次执行上面的两条 SQL:
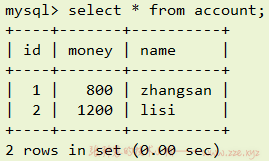
这时候会发现表数据好像是正常修改了。但这只是此时内存中的数据,并没有持久化保存到 db,我们可以通过 navicat 查看一下表数据:

此时我们再执行一下 commit 提交事务:

再次使用 navicat 查看表数据:
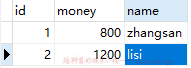
此时上述的更新操作就持久化到了 db,这就是事务的提交 (commit) 操作。
假如我们在上一步不执行 commit 操作,而是执行 rollback 也就是回滚操作:
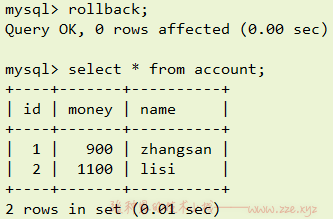
可以看到数据又回到更新前的初始状态,这就是事务的回滚 (rollback) 操作。
这种修改自动提交的方式默认只是局部针对当前会话连接,对其它连接没有影响,还可设置全局自动提交如下:
set [session] autocommit=[0|1]; // 默认 设置会话级事务自动提交
set global autocommit=[0|1]; // 全局级事务自动提交
方式二:手动开启事务
除了如方式一修改 MySQL 事务的自动提交这种方式,MySQL 还为我们提供了手动开始事务的方式。
可通过 start transaction 开启事务:

提交和回滚事务也都是通过 commit 和 rollback 。
以上两条 DML 语句必须同时成功或者同时失败,最小单元不可再分。当第一条 DML 语句执行成功后,并不能将底层数据库中的第一个账户的数据修改,只是将操作记录了一下,这个记录是在内存中完成的;当第二条 DML 语句执行成功后,和底层数据库文件中的数据完成同步。若第二条 DML 语句执行失败,则清空所有的历史操作记录,要完成以上的功能必须借助事务。
事务四大特征 (ACID)
原子性 (Atomicity):事务是最小单位,不可再分。
一致性 (Consistency):事务要求所有的 DML 语句操作的时候,必须保证同时成功或者同时失败。
隔离性 (Isolation):事务 A 和事务 B 之间具有隔离性。
持久性 (Durability):是事务的保证,事务终结的标志(内存的数据持久到硬盘文件中)。
事务开启与结束的标志
开启标志:任何一条 DML 语句 (insert、update、delete) 执行,标志事务的开启。
结束标志:
- 提交:成功的结束,将所有的 DML 语句操作历史记录和底层硬盘数据来一次同步。
- 回滚:失败的结束,将所有的 DML 语句操作历史记录全部清空。
隔离性(Isolation)
事务的隔离级别
事务 A 和事务 B 之间具有一定的隔离性,有 4 个隔离级别。
read uncommitted(读未提交)
-
事务 A 和事务 B,事务 A 未提交的数据,事务 B 可以读取到。
-
这里读取到的数据叫做“脏数据”。
-
这种隔离级别最低,这种级别一般是在理论上存在,数据库隔离级别一般都高于该级别。
read committed(读已提交)
-
事务 A 和事务 B ,事务A提交的数据,事务 B 才能读取到。
-
这种隔离级别高于读未提交。
-
换句话说,对方事务提交之后的数据,我当前事务才能读取到。
-
这种级别可以避免“脏数据”。
-
这种隔离级别会导致“不可重复读取”。
-
Oracle 默认隔离级别。
repeatable read(可重复读)
-
事务 A 和事务 B,事务 A 提交之后的数据,事务 B 读取不到。
-
事务 B 是可重复读取数据。
-
这种隔离级别高于读已提交。
-
换句话说,对方提交之后的数据,我还是读取不到。
-
这种隔离级别可以避免“不可重复读取”,达到可重复读取。
-
比如 1 点和 2 点读到数据是同一个。
-
Mysql 默认级别。
-
虽然可以达到可重复读取,但是会导致“幻像读”。
serializable(串行化)
-
事务 A 和事务 B,事务 A 在操作数据库时,事务 B 只能排队等待。
-
这种隔离级别很少使用,吞吐量太低,用户体验差。
-
这种级别可以避免“幻像读”,每一次读取的都是数据库中真实存在数据,事务 A 与事务 B 串行,而不并发。
-
脏读:一个事务读到了另一个事务未提交的数据。
-
不可重复读:一个事务读到了另一个事务已提交的数据,造成前后两次查询结果不一致。
-
幻读:一个事务读到了另一个事务 insert 的数据,造成前后两次查询结果不一致(mysql 为 innoDB 引擎时不存在这个问题)。
隔离级别与一致性关系
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 读未提交 | 可能 | 可能 | 可能 |
| 读已提交 | 不可能 | 可能 | 可能 |
| 可重复读 | 不可能 | 不可能 | 对 InnoDB 不可能 |
| 串行化 | 不可能 | 不可能 | 不可能 |
设置事务的隔离级别
方式一:修改配置文件
MySQL 可以在 my.ini 文件中使用 transaction-isolation 选项来设置服务器的缺省事务隔离级别。
值可以是:
READ-UNCOMMITTEDREAD-COMMITTEDREPEATABLE-READSERIALIZABLE
例:
[mysqld]
transaction-isolation = READ-COMMITTED
方式二:命令动态设置
隔离级别也可以在运行的服务器中动态设置,应使用 SET TRANSACTION ISOLATION LEVEL 语句。
语法:
SET [GLOBAL | SESSION] TRANSACTION ISOLATION LEVEL <isolation-level>
[GLOBAL]:全局级设置,对所有会话有效。
[SESSION]:默认级别,会话级设置,只对当前会话有效。
<isolation-level>:
– READ UNCOMMITTED
– READ COMMITTED
– REPEATABLE READ
– SERIALIZABLE
例:
SET TRANSACTION ISOLATION LEVEL REPEATABLE READ;
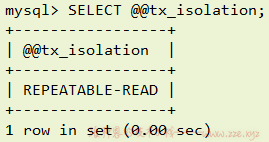
要查看当前事务隔离级别,执行
SELECT @@tx_isolation;即可:
丢失更新问题
假如有如下账户表:

分析
现在同时有 A 和 B 两个事务操作,A 要修改 id 为 1 的 name 为 zhangsansan,B 要修改 id 为 1 的 money 为 2000,此时必然有一个事务是先提交的。 假如 A 先提交,此时 id 为 1 的 name 已修改为 zhangsansan。此时问题就出现了,因为 B 的修改信息现在还在内存中,B 这里的 name 还是之前的 zhangsan,提交后就会覆盖 A 的修改内容,最后将数据修改为:
id money name
1 2000 zhangsan
此时,A 的更新内容就丢失了。
解决丢失更新有如下两种常用方式:
悲观锁(排他锁)
用 MySQL 测试上面示例,我们会发现并没有出现上述分析情况,原因就是排他锁。
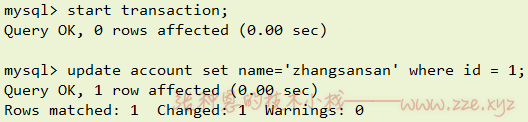
A 窗口,开启事务,更新数据,但不提交:
B 窗口,开启事务,执行更新操作,会发现阻塞住了:
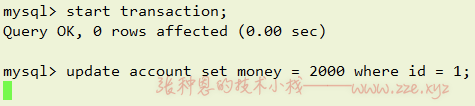
当 A 窗口事务提交,B 窗口的阻塞会立马消失,接着执行完毕。这是因为在 MySQL 的事务中执行更新操作时会给要更新的数据加上排他锁,如果当前更新事务未提交,那么此时其它事务对该数据的更新操作就会被阻塞至当前事务提交(排他锁释放),当前事务提交后,其它事务就能拿到最新的数据在最新数据的基础上更新,就不会出现分析中丢失更新的情况。
还可以通过查询操作主动给表或行加排他锁,例如:
select * from account where id=1 for update;
乐观锁
与悲观锁不同,悲观锁是由数据库机制提供,而乐观锁是需要开发者手动控制的。修改表结构,给 account 表添加一个 version 字段:
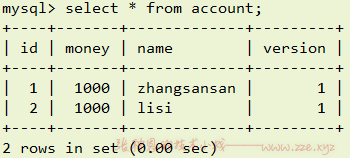
只是要使用乐观锁的方式我们就需要做一些额外的操作,比如:
在事务提交之前,需要先检查当前内存行数据 version 和对应 db 实际行数据 version 是否相同,如果相同,则提交更新,如果当前 version 小于实际 version,就将当前数据更新到实际 version 对应的数据,然后在该数据的基础上执行我们自己的更新操作,并且将 version 自增 1 后提交。
依然以上面示例说明,在 A 事务将 id 为 1 的 name 改为 zhangsansan 提交后,该条数据 version 版本此时就为 1。B 事务接着提交,当它以上述方式检查当前内存 version 时,会发现当前内存 version 为 0,而实际对应数据 version 为 1,它就要将内存数据更新为 version 为 1 对应的这个版本了。即 name 同步为 zhangsan,接着在这个基础上执行自己的修改操作,将 money 修改为 2000,所以更新后的结果为:
id money name
1 2000 zhangsansan
这种方式也不会丢失更新,究其根底其实它的原理还是和悲观锁相同:就是保证事务能在最新的数据基础上更新。
评论区