-de8bd8f33c3e44a59907dafe1884f228.png)




介绍
Galera Cluster 是由 Codership 开发的 MySQL 多主集群,包含在 MariaDB 中,同时支持 Percona xtradb、MySQL,是一个易于使用的高可用解决方案,在数据完整性、可扩展性及高性能方面都有可接受的表现。
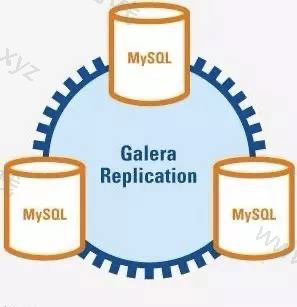
下图所示为一个三节点 Galera 集群,三个 MySQL 实例是对等的,互为主从,这被称为多主(multi-master)架构。当客户端读写数据时,可连接任一 MySQL 实例。对于读操作,从每个节点读取到的数据都是相同的。对于写操作,当数据写入某一节点后,集群会将其同步到其它节点。这种架构不共享任何数据,是一种高冗余架构。
为什么需要 Galera Cluster
MySQL 在互联网时代,可谓是深受世人瞩目的。给社会创造了无限价值,随之而来的是,在 MySQL 基础之上,产生了形形色色的使用方法、架构及周边产品。在这方面,已经有很多成熟的被人熟知的产品,比如 MHA、MMM 等传统组织架构,而这些架构是每个需要数据库高可用服务方案的入门必备选型。
不幸的是,传统架构的使用,一直被人们所诟病,因为 MySQL 的主从模式,天生的不能完全保证数据一致,很多大公司会花很大人力物力去解决这个问题,而效果却一般,可以说,只能是通过牺牲性能,来获得数据一致性,但也只是在降低数据不一致性的可能性而已。所以现在就急需一种新型架构,从根本上解决这样的问题,天生的摆脱掉主从复制模式这样的美中不足之处了。
幸运的是,MySQL 的福音来了,Galera Cluster 就是我们需要的——从此变得完美的架构。
相比传统的主从复制架构,Galera Cluster 解决的最核心问题是,在三个实例(节点)之间,它们的关系是对等的,multi-master 架构的,在多节点同时写入的时候,能够保证整个集群数据的一致性,完整性与正确性。
在传统 MySQL 的使用过程中,也不难实现一种 multi-master 架构,但是一般需要上层应用来配合,比如先要约定每个表必须要有自增列,并且如果是 2 个节点的情况下,一个节点只能写偶数的值,而另一个节点只能写奇数的值,同时 2 个节点之间互相做复制,因为 2 个节点写入的东西不同,所以复制不会冲突,在这种约定之下,可以基本实现多 master 的架构,也可以保证数据的完整性与一致性。但这种方式使用起来还是有限制,同时还会出现复制延迟,并且不具有扩展性,不是真正意义上的集群。
Galera Cluster 如何解决上述问题
现在已经知道,Galera Cluster 是 MySQL 封装了具有高一致性,支持多点写入的同步通信模块 Galera 而做的,它是建立在 MySQL 同步基础之上的,使用 Galera Cluster 时,应用程序可以直接读、写某个节点的最新数据,并且可以在不影响应用程序读写的情况下,下线某个节点,因为支持多点写入,使得 Failover 变得非常简单。
所有的 Galera Cluster,都是对 Galera 所提供的接口 API 做了封装,这些 API 为上层提供了丰富的状态信息及回调函数,通过这些回调函数,做到了真正的多主集群,多点写入及同步复制,这些 API 被称作是 Write-Set Replication API,简称为 wsrep API。
通过这些 API,Galera Cluster 提供了基于验证的复制,是一种乐观的同步复制机制,一个将要被复制的事务(称为写集),不仅包括被修改的数据库行,还包括了这个事务产生的所有 Binlog,每一个节点在复制事务时,都会拿这些写集与正在 APPLY 队列的写集做比对,如果没有冲突的话,这个事务就可以继续提交,或者是 APPLY,这个时候,这个事务就被认为是提交了,然后在数据库层面,还需要继续做事务上的提交操作。
这种方式的复制,也被称为是虚拟同步复制,实际上是一种逻辑上的同步,因为每个节点的写入和提交操作还是独立的,更准确的说是异步的,Galera Cluster 是建立在一种乐观复制的基础上的,假设集群中的每个节点都是同步的,那么加上在写入时,都会做验证,那么理论上是不会出现不一致的,当然也不能这么乐观,如果出现不一致了,比如主库(相对)插入成功,而从库则出现主键冲突,那说明此时数据库已经不一致,这种时候 Galera Cluster 采取的方式是将出现不一致数据的节点踢出集群,其实是自己 shutdown 了。
而通过使用 Galera,它在里面通过判断键值的冲突方式实现了真正意义上的 multi-master,Galera Cluster 在 MySQL 生态中,在高可用方面实现了非常重要的提升,目前 Galera Cluster 具备的功能包括如下几个方面:
- 多主架构: 真正的多点读写的集群,在任何时候读写数据,都是最新的。
- 同步复制: 集群不同节点之间数据同步,没有延迟,在数据库挂掉之后,数据不会丢失。
- 并发复制: 从节点在 APPLY 数据时,支持并行执行,有更好的性能表现。
- 故障切换: 在出现数据库故障时,因为支持多点写入,切的非常容易。
- 热插拔: 在服务期间,如果数据库挂了,只要监控程序发现的够快,不可服务时间就会非常少。在节点故障期间,节点本身对集群的影响非常小。
- 自动节点克隆: 在新增节点,或者停机维护时,增量数据或者基础数据不需要人工手动备份提供,Galera Cluster 会自动拉取在线节点数据,最终集群会变为一致。
- 对应用透明: 集群的维护,对应用程序是透明的,几乎感觉不到。 以上几点,足以说明 Galera Cluster 是一个既稳健,又在数据一致性、完整性及高性能方面有出色表现的高可用解决方案。
注意点
在运维过程中,有些技术特点还是需要注意的,这样才能做到知此知彼,百战百胜,因为现在 MySQL 主从结构的集群已经都是被大家所熟知的了,而 Galera Cluster 是一个新的技术,是一个在不断成熟的技术,所以很多想了解这个技术的同学,能够得到的资料很少,除了官方的手册之外,基本没有一些讲得深入的,用来传道授业解惑的运维资料,这无疑为很多同学设置了不低的门槛,最终有很多人因为一些特性,导致最终放弃了 Galera Cluster 的选择。
目前熟知的一些特性,或者在运维中需要注意的一些特性,有以下几个方面:
- Galera Cluster 写集内容: Galera Cluster 复制的方式,还是基于 Binlog 的,这个问题,也是一直被人纠结的,因为目前 Percona Xtradb Cluster 所实现的版本中,在将 Binlog 关掉之后,还是可以使用的,这误导了很多人,其实关掉之后,只是不落地了,表象上看上去是没有使用 Binlog 了,实际上在内部还是悄悄的打开了的。除此之外,写集中还包括了事务影响的所有行的主键,所有主键组成了写集的 KEY,而 Binlog 组成了写集的 DATA,这样一个 KEY-DATA 就是写集。KEY 和 DATA 分别具有不同的作用的,KEY 是用来验证的,验证与其它事务没有冲突,而 DATA 是用来在验证通过之后,做 APPLY 的。
- Galera Cluster 的并发控制: 现在都已经知道,Galera Cluster 可以实现集群中,数据的高度一致性,并且在每个节点上,生成的 Binlog 顺序都是一样的,这与 Galera 内部,实现的并发控制机制是分不开的。所有的上层到下层的同步、复制、执行、提交都是通过并发控制机制来管理的。这样才能保证上层的逻辑性,下层数据的完整性等。
适用场景
现在对 Galera Cluster 已经有了足够了解,但这样的“完美”架构,在什么场景下才可以使用呢?或者说,哪种场景又不适合使用这样的架构呢?针对它的缺点,及优点,我们可以扬其长,避其短。可以通过下面几个方面,来了解其适用场景。
- 数据强一致性: 因为 Galera Cluster,可以保证数据强一致性的,所以它更适合应用于对数据一致性和完整性要求特别高的场景,比如交易,正是因为这个特性,去哪儿网才会成为使用 Galera Cluster 的第一大户。
- 多点写入: 这里要强调多点写入的意思,不是要支持以多点写入的方式提供服务,更重要的是,因为有了多点写入,才会使得在 DBA 正常维护数据库集群的时候,才会不影响到业务,做到真正的无感知,因为只要是主从复制,就不能出现多点写入,从而导致了在切换时,必然要将老节点的连接断掉,然后齐刷刷的切到新节点,这是没办法避免的,而支持了多点写入,在切换时刻允许有短暂的多点写入,从而不会影响老的连接,只需要将新连接都路由到新节点即可。这个特性,对于交易型的业务而言,也是非常渴求的。
- 性能: Galera Cluster,能支持到强一致性,毫无疑问,也是以牺牲性能为代价,争取了数据一致性,但要问:”性能牺牲了,会不会导致性能太差,这样的架构根本不能满足需求呢?”这里只想说的是,这是一个权衡过程,有多少业务,QPS 大到 Galera Cluster 不能满足的?我想是不多的(当然也是有的,可以自行做一些测试),在追求非常高的极致性能情况下,也许单个的 Galera Cluster 集群是不能满足需求的,但毕竟是少数了,所以够用就好,Galera Cluster 必然是 MySQL 方案中的佼佼者。
上述内容摘自:https://blog.csdn.net/wo18237095579/article/details/81270954。
实践
环境准备
准备如下几台主机:
| 主机名 | IP | OS |
|---|---|---|
| node1 | 10.0.1.200 | CentOS 7 |
| node2 | 10.0.1.201 | CentOS 7 |
| node3 | 10.0.1.202 | CentOS 7 |
1、点击下载galera cluster 版的 MySQL 二进制包,在如上三个主机安装,安装过程同「二进制包形式安装 MySQL5.7」。
没梯子的朋友可以走百度云【链接: https://pan.baidu.com/s/1OgzjZ1N6LTi52XNbRhU0vA 密码: ev93】。
2、在三台主机上安装 galera 库:
$ yum install galera -y
配置及启动
1、修改 node1 的配置文件:
$ cat << EOF > /etc/my.cnf
[mysqld]
user=mysql
basedir=/data/app/mysql
datadir=/data/3306/data
socket=/tmp/mysql.sock
binlog-format=row
# 监听地址
bind-address=0.0.0.0
# galera 库文件位置,可通过 rpm -ql galera | grep '_smm.so' 查看
wsrep_provider=/usr/lib64/galera/libgalera_smm.so
# 指定 wsrep 启动端口号,4567 为默认值
wsrep_provider_options='gmcast.listen_addr=tcp://10.0.1.200:4567'
# galera集群的名字,必须是统一的
wsrep_cluster_name='my_wsrep_cluster'
# 集群中的其他节点地址,可以使用主机名或 IP
wsrep_cluster_address='gcomm://10.0.1.200:4567,10.0.1.201:4567,10.0.1.202:4567'
# 当前节点名称
wsrep_node_name=node1
# 当前节点地址
wsrep_node_address='10.0.1.200'
# 集群同步方式,下述配置则需要安装 rsync 程序包
wsrep_sst_method=rsync
# 集群同步的用户名密码
wsrep_sst_auth=root:123
# 一个逗号分割的节点串作为状态转移源,下述表示:如果 node1 不可用,用 node2,如果 node2 不可用,用node3,最后的逗号表明让提供商自己选择一个最优的
wsrep_sst_donor='node1,node2,node3,'
[mysql]
socket=/tmp/mysql.sock
EOF
2、修改 node2 的配置文件:
$ cat << EOF > /etc/my.cnf
[mysqld]
user=mysql
basedir=/data/app/mysql
datadir=/data/3306/data
socket=/tmp/mysql.sock
binlog-format=row
bind-address=0.0.0.0
wsrep_provider=/usr/lib64/galera/libgalera_smm.so
wsrep_provider_options='gmcast.listen_addr=tcp://10.0.1.201:4567'
wsrep_cluster_name='my_wsrep_cluster'
wsrep_cluster_address='gcomm://10.0.1.200:4567,10.0.1.201:4567,10.0.1.202:4567'
wsrep_node_name=node2
wsrep_node_address='10.0.1.201'
wsrep_sst_method=rsync
wsrep_sst_auth=root:123
wsrep_sst_donor='node1,node2,node3,'
[mysql]
socket=/tmp/mysql.sock
EOF
3、修改 node3 的配置文件:
$ cat << EOF > /etc/my.cnf
[mysqld]
user=mysql
basedir=/data/app/mysql
datadir=/data/3306/data
socket=/tmp/mysql.sock
binlog-format=row
bind-address=0.0.0.0
wsrep_provider=/usr/lib64/galera/libgalera_smm.so
wsrep_provider_options='gmcast.listen_addr=tcp://10.0.1.202:4567'
wsrep_cluster_name='my_wsrep_cluster'
wsrep_cluster_address='gcomm://10.0.1.200:4567,10.0.1.201:4567,10.0.1.202:4567'
wsrep_node_name=node3
wsrep_node_address='10.0.1.202'
wsrep_sst_method=rsync
wsrep_sst_auth=root:123
wsrep_sst_donor='node1,node2,node3,'
[mysql]
socket=/tmp/mysql.sock
EOF
4、执行下面命令启动 node1 主机的 MySQL:
$ /etc/init.d/mysqld start --wsrep-new-cluster
5、启动 node2、node3 的 MySQL:
$ systemctl start mysqld
测试数据同步
1、在 node1 中创建数据库:
mysql> create database testdb;
Query OK, 1 row affected (0.01 sec)
2、在 node2 中检查是否同步创建了上面的数据库:
mysql> show databases like 'testdb';
+-------------------+
| Database (testdb) |
+-------------------+
| testdb |
+-------------------+
1 row in set (0.00 sec)
3、在 node2 中进入 testdb 数据库创建表并录入数据:
mysql> use testdb;
Database changed
mysql> create table t1 (id int primary key auto_increment, name varchar(24));
Query OK, 0 rows affected (0.01 sec)
mysql> insert into t1(name) values('zs'),('ls');
Query OK, 2 rows affected (0.00 sec)
Records: 2 Duplicates: 0 Warnings: 0
4、在 node3 中检查是否同步了上述的库、表及数据:
mysql> use testdb;
Database changed
mysql> select * from t1;
+----+------+
| id | name |
+----+------+
| 2 | zs |
| 5 | ls |
+----+------+
2 rows in set (0.00 sec)
评论区